《大话设计模式》提炼
本笔记是阅读了《大话设计模式》后的知识提炼,时常翻阅,温故知新。
1. 面向对象
面向对象优点:可维护;可复用;可扩展;灵活性好。
面向对象三大特性是封装、继承和多态。
当你的代码中重复的代码多到一定程度,维护的时候,可能就是一场灾难。让业务逻辑与界面逻辑分开,让它们之间的耦合度下降。只有分离开,才可以达到容易维护或扩展。
面向对象的编程,并不是类越多越好,类的划分是为了封装,但分类的基础是抽象,具有相同属性和功能的对象的抽象集合才是类。好比商品打折,打一折和打九折只是形式的不同,抽象分析出来,所有的打折算法都是一样的,所以打折算法应该是一个类。
1.1 UML图
UML图样例:
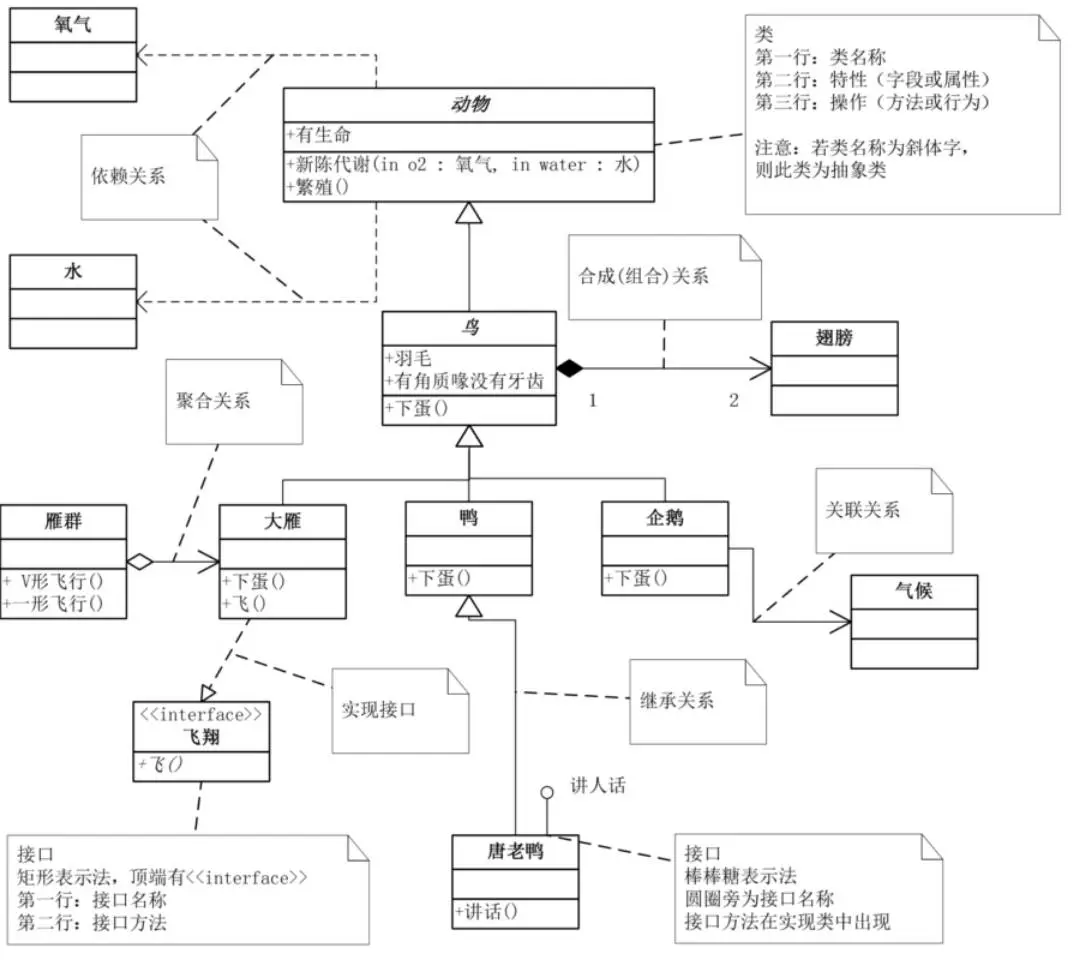
‘动物’矩形框,它就代表一个类(Class)。类类图分三层,第一层显示类的名称,如果是抽象类,则就用斜体显示。第二层是类的特性,通常就是字段和属性。第三层是类的操作,通常是方法或行为。注意前面的符号,‘+’表示public,‘-’表示private,‘#’表示protected。
左下角的‘飞翔’,它表示一个接口图,与类图的区别主要是顶端有<
接口还有另一种表示方法,俗称棒棒糖表示法,比如图中的唐老鸭类就是实现了‘讲人话’的接口。
注意动物、鸟、鸭、唐老鸭之间关系符号。它们都是继承的关系,继承关系用空心三角形+实线来表示。(我继承自你,所以我指向你)
大雁是最能飞的,让它实现了飞翔接口。实现接口用空心三角形+虚线来表示。(我实现了你,所以我指向你)
企鹅和气候两个类,企鹅是很特别的鸟,会游不会飞。更重要的是,它与气候有很大的关联。企鹅需要‘知道’气候的变化,需要‘了解’气候规律。当一个类‘知道’另一个类时,可以用关联(association)。关联关系用实线箭头来表示。(我中有你,所以我指向你。)
大雁与雁群这两个类,大雁是群居动物,每只大雁都是属于一个雁群,一个雁群可以有多只大雁。所以它们之间就满足聚合(Aggregation)关系。聚合表示一种弱的‘拥有’关系,体现的是A对象可以包含B对象,但B对象不是A对象的一部分。
合成(Composition,也有翻译成‘组合’的)是一种强的‘拥有’关系,体现了严格的部分和整体的关系,部分和整体的生命周期一样。在这里鸟和其翅膀就是合成(组合)关系,因为它们是部分和整体的关系,并且翅膀和鸟的生命周期是相同的。合成关系用实心的菱形+实线箭头来表示。另外,你会注意到合成关系的连线两端还有一个数字‘1’和数字‘2’,这被称为基数。表明这一端的类可以有几个实例,很显然,一个鸟应该有两只翅膀。如果一个类可能有无数个实例,则就用‘n’来表示。关联关系、聚合关系也可以有基数的。
动物几大特征,比如有新陈代谢,能繁殖。而动物要有生命力,需要氧气、水以及食物等。也就是说,动物依赖于氧气和水。他们之间是依赖关系(Dependency),用虚线箭头来表示。
2. 设计原则
2.1 单一职责原则
大多数时候,一件产品简单一些,职责单一一些,或许是更好的选择。这就和设计模式中的一大原则——单一职责原则(SRP)的道理是一样的:,就一个类而言,应该仅有一个引起它变化的原因
它的准确解释是,就一个类而言,应该仅有一个引起它变化的原因。我们在做编程的时候,很自然地就会给一个类加各种各样的功能,比如我们写一个窗体应用程序,一般都会生成一个Form1这样的类,于是我们就把各种各样的代码,像某种商业运算的算法呀,像数据库访问的SQL语句呀什么的都写到这样的类当中,这就意味着,无论任何需求要来,你都需要更改这个窗体类,这其实是很糟糕的,维护麻烦,复用不可能,也缺乏灵活性。
如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏。软件设计真正要做的许多内容,就是发现职责并把那些职责相互分离。要去判断是否应该分离出类来,也不难,那就是如果你能够想到多于一个的动机去改变一个类,那么这个类就具有多于一个的职责,就应该考虑类的职责分离。
好比做游戏,界面的变化是和游戏本身没有关系的,界面是容易变化的,而游戏逻辑是不太容易变化的,将它们分离开有利于界面的改动。
做到单一职责,这样你的代码才是真正的易维护、易扩展、易复用、灵活多样。
2.2 开放-封闭原则
开放-封闭原则,是说软件实体(类、模块、函数等等)应该可以扩展,但是不可修改。这个原则其实是有两个特征,一个是说‘对于扩展是开放的(Open for extension)’,另一个是说‘对于更改是封闭的(Closed for modification)’
我们在做任何系统的时候,都不要指望系统一开始时需求确定,就再也不会变化,这是不现实也不科学的想法,而既然需求是一定会变化的,那么如何在面对需求的变化时,设计的软件可以相对容易修改,不至于说,新需求一来,就要把整个程序推倒重来。怎样的设计才能面对需求的改变却可以保持相对稳定,从而使得系统可以在第一个版本以后不断推出新的版本呢?,开放-封闭给我们答案。
开放-封闭原则的意思就是说,你设计的时候,时刻要考虑,尽量让这个类是足够好,写好了就不要去修改了,如果新需求来,我们增加一些类就完事了,原来的代码能不动则不动。
无论模块是多么的‘封闭’,都会存在一些无法对之封闭的变化。既然不可能完全封闭,设计人员必须对于他设计的模块应该对哪种变化封闭做出选择。他必须先猜测出最有可能发生的变化种类,然后构造抽象来隔离那些变化。
面对需求,对程序的改动是通过增加新代码进行的,而不是更改现有的代码。
我们希望的是在开发工作展开不久就知道可能发生的变化。查明可能发生的变化所等待的时间越长,要创建正确的抽象就越困难。所以要尽早做出改变,当变化发生时,我们就创建抽象来隔离以后发生的同类变化,避免工作的重复叠加。
开放-封闭原则是面向对象设计的核心所在。遵循这个原则可以带来面向对象技术所声称的巨大好处,也就是可维护、可扩展、可复用、灵活性好。开发人员应该仅对程序中呈现出频繁变化的那些部分做出抽象,然而,对于应用程序中的每个部分都刻意地进行抽象同样不是一个好主意。拒绝不成熟的抽象和抽象本身一样重要。
2.3 依赖倒转原则
依赖倒转原则,也有翻译成依赖倒置原则的。依赖倒转原则,原话解释是抽象不应该依赖细节,细节应该依赖于抽象,这话绕口,说白了,就是要针对接口编程,不要对实现编程。好比CPU只需要把接口定义好,内部再复杂我也不让外界知道,而主板只需要预留与CPU针脚的插槽就可以了,CPU就是抽象,内部的电路是细节,但是我们不需要关注抽象的内部细节,而只需要知道接口就可以使用它,这是针对接口编程的思想。无论主板、CPU、内存、硬盘都是在针对接口设计的,而如果针对实现来设计,内存就要对应到具体的某个品牌的主板,那就会出现换内存需要把主板也换了的尴尬,这就是针对实现编程的思想,会很麻烦。
A.高层模块不应该依赖低层模块。两个都应该依赖抽象。
B.抽象不应该依赖细节。细节应该依赖抽象。
面向过程的开发时,为了使得常用代码可以复用,一般都会把这些常用代码写成许许多多函数的程序库,这样我们在做新项目时,去调用这些低层的函数就可以了。比如我们做的项目大多要访问数据库,所以我们就把访问数据库的代码写成了函数,每次做新项目时就去调用这些函数。这也就叫做高层模块依赖低层模块。
然而我们要做新项目时,发现业务逻辑的高层模块都是一样的,但客户却希望使用不同的数据库或存储信息方式,这时就出现麻烦了。我们希望能再次利用这些高层模块,但高层模块都是与低层的访问数据库绑定在一起的,没办法复用这些高层模块,这就非常糟糕了。
PC里如果CPU、内存、硬盘都需要依赖具体的主板,主板一坏,所有的部件就都没用了,这显然不合理。反过来,如果内存坏了,也不应该造成其他部件不能用才对。而如果不管高层模块还是低层模块,它们都依赖于抽象,具体一点就是接口或抽象类,只要接口是稳定的,那么任何一个的更改都不用担心其他受到影响,这就使得无论高层模块还是低层模块都可以很容易地被复用。这才是最好的办法。
这里不得不提里氏代换原则,它的含义是一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化,简单地说,子类型必须能够替换掉它们的父类型。
也正因为有了这个原则,使得继承复用成为了可能,只有当子类可以替换掉父类,软件单位的功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为。
由于子类型的可替换性才使得使用父类类型的模块在无需修改的情况下就可以扩展,这是扩展开放。高层模块不应该依赖低层模块,两个都应该依赖抽象,这是修改封闭。
依赖倒转其实就是谁也不要依靠谁,除了约定的接口,大家都可以灵活自如。依赖倒转的倒转,感觉可以把它理解为把互相的依赖关系倒转为互相依赖接口。依赖接口后,因为满足里氏替换原则,接口的子类替换不会影响接口的行为,所以可以用更换子类的方式实现程序模块的“可热插拔”。
依赖倒转其实可以说是面向对象设计的标志,用哪种语言来编写程序不重要,如果编写时考虑的都是如何针对抽象编程而不是针对细节编程,即程序中所有的依赖关系都是终止于抽象类或者接口,那就是面向对象的设计,反之那就是过程化的设计了。
2.4 迪米特法则
迪米特法则(LoD)’也叫最少知识原则。意思是如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。
迪米特法则首先强调的前提是在类的结构设计上,每一个类都应当尽量降低成员的访问权限,一个类包装好自己的private状态,不需要让别的类知道的字段或行为就不要公开。迪米特法则其根本思想,是强调了类之间的松耦合。类之间的耦合越弱,越有利于复用,一个处在弱耦合的类被修改,不会对有关系的类造成波及。
2.5 合成/聚合复用原则
在面向对象设计中,我们还有一个很重要的设计原则,那就是合成/聚合复用原则。即优先使用对象合成/聚合,而不是类继承。
合成/聚合复用原则(CARP),尽量使用合成/聚合,尽量不要使用类继承。
合成(Composition,也有翻译成组合)和聚合(Aggregation)都是关联的特殊种类。聚合表示一种弱的‘拥有’关系,体现的是A对象可以包含B对象,但B对象不是A对象的一部分;合成则是一种强的‘拥有’关系,体现了严格的部分和整体的关系,部分和整体的生命周期一样。比方说,大雁有两个翅膀,翅膀与大雁是部分和整体的关系,并且它们的生命周期是相同的,于是大雁和翅膀就是合成关系。而大雁是群居动物,所以每只大雁都是属于一个雁群,一个雁群可以有多只大雁,所以大雁和雁群是聚合关系。
合成/聚合复用原则的好处是,优先使用对象的合成/聚合将有助于你保持每个类被封装,并被集中在单个任务上。这样类和类继承层次会保持较小规模,并且不太可能增长为不可控制的庞然大物。就刚才的例子,你需要学会用对象的职责,而不是结构来考虑问题。其实答案就在之前我们聊到的手机与PC电脑的差别上。
3. 设计模式
书中总共概括了5种创建型模式,7种结构型模式和12种行为型模式。
3.1 创建型模式
3.1.1 简单工厂模式
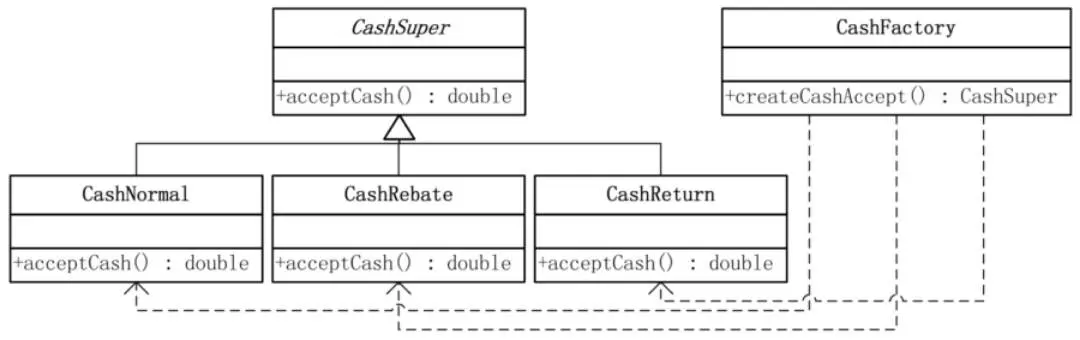
简单工厂模式’,也就是说,到底要实例化谁,将来会不会增加实例化的对象,比如增加开根运算,这是很容易变化的地方,应该考虑用一个单独的类来做这个创造实例的过程,这就是工厂
简单工厂模式只是解决对象的创建问题,而且由于工厂本身包括了所有的算法实现方式,这些实现方式可能是经常需要改动的,每次维护或扩展都要改动这个工厂,以致代码需重新编译部署,这真的是很糟糕的处理方式,所以用它不是最好的办法。面对算法的时常变动,应该有更好的办法。
3.1.2 建造者模式
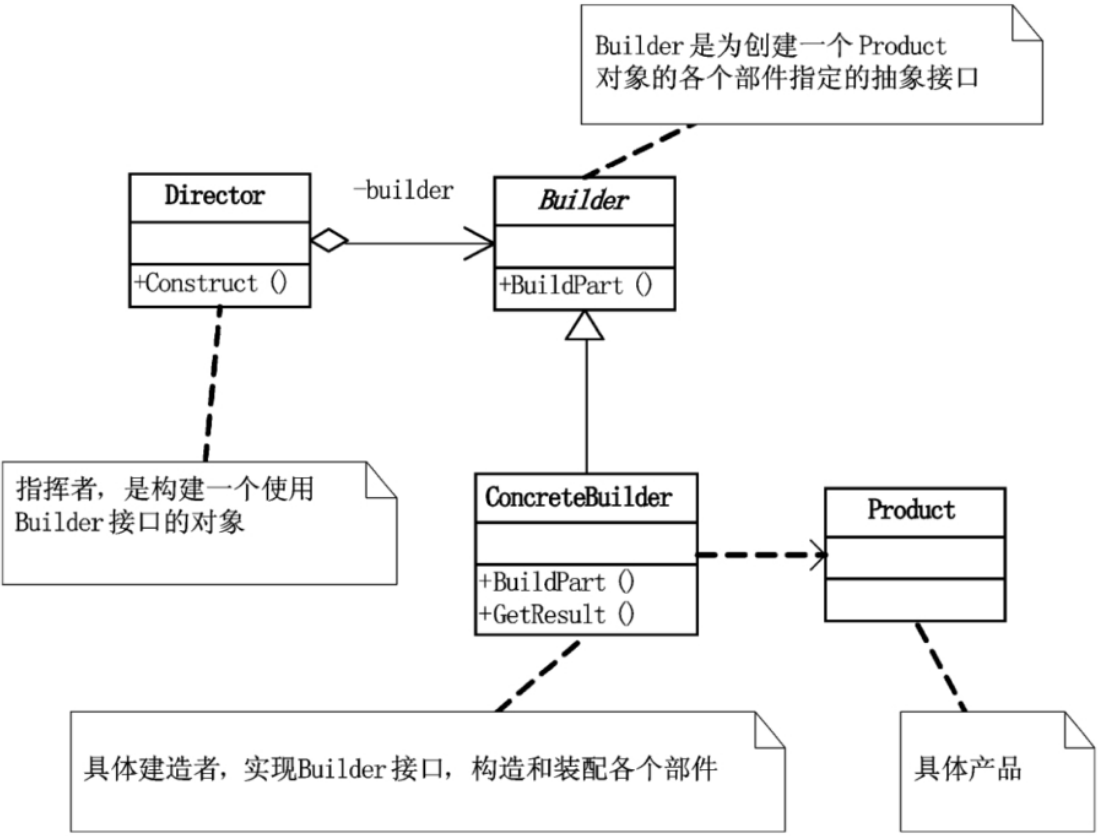
如果你需要将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示的意图时,我们需要应用于一个设计模式,‘建造者(Builder)模式’,又叫生成器模式。建造者模式可以将一个产品的内部表象与产品的生成过程分割开来,从而可以使一个建造过程生成具有不同的内部表象的产品对象。如果我们用了建造者模式,那么用户就只需指定需要建造的类型就可以得到它们,而具体建造的过程和细节就不需知道了。
建造者模式(Builder),将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
建造者模式中有一个很重要的类,指挥者(Director),用它来控制建造过程,也用它来隔离用户与建造过程的关联。
建造者模式是逐步建造产品的,所以建造者的Builder类里的那些建造方法必须要足够普遍,以便为各种类型的具体建造者构造。
它主要是用于创建一些复杂的对象,这些对象内部构建间的建造顺序通常是稳定的,但对象内部的构建通常面临着复杂的变化。
建造者模式的好处就是使得建造代码与表示代码分离,由于建造者隐藏了该产品是如何组装的,所以若需要改变一个产品的内部表示,只需要再定义一个具体的建造者就可以了。
3.1.3 工厂模式
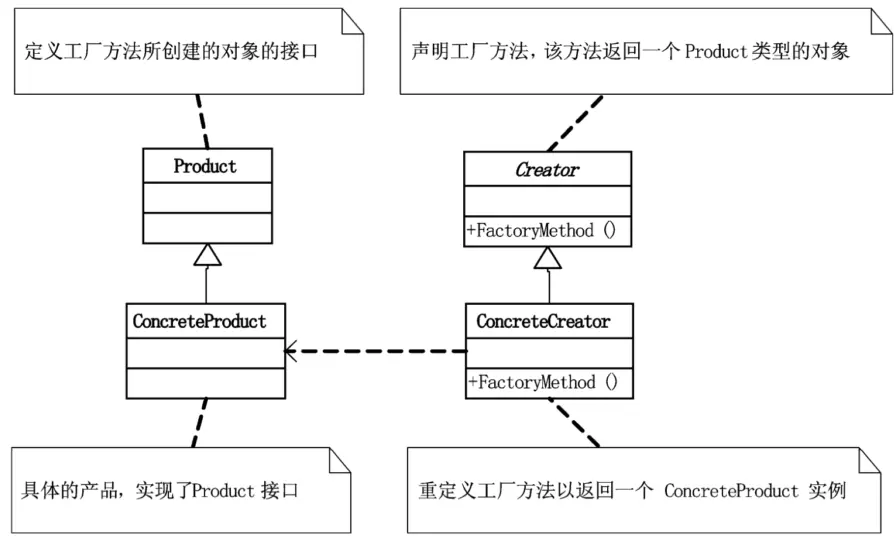
简单工厂模式的最大优点在于工厂类中包含了必要的逻辑判断,根据客户端的选择条件动态实例化相关的类,对于客户端来说,去除了与具体产品的依赖。
好比如果我们要在计算器功能加一个‘求M数的N次方’的功能,我们是一定需要给运算工厂类的方法里加‘Case’的分支条件的,修改原有的类?这可不是好办法,这就等于说,我们不但对扩展开放了,对修改也开放了,这样就违背了开放封闭原则。
工厂方法模式(Factory Method),定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
既然这个工厂类与分支耦合,那么我就对它下手,根据依赖倒转原则,我们把工厂类抽象出一个接口,这个接口只有一个方法,就是创建抽象产品的工厂方法。然后,所有的要生产具体类的工厂,就去实现这个接口,这样,一个简单工厂模式的工厂类,变成了一个工厂抽象接口和多个具体生成对象的工厂,于是我们要增加‘求M数的N次方’的功能时,就不需要更改原有的工厂类了,只需要增加此功能的运算类和相应的工厂类就可以了。
这样整个工厂和产品体系其实都没有修改的变化,而只是扩展的变化,这就完全符合了开放-封闭原则的精神。
工厂方法模式实现时,客户端需要决定实例化哪一个工厂来实现运算类,选择判断的问题还是存在的,也就是说,工厂方法把简单工厂的内部逻辑判断移到了客户端代码来进行。你想要加功能,本来是改工厂类的,而现在是修改客户端。
工厂方法克服了简单工厂违背开放-封闭原则的缺点,又保持了封装对象创建过程的优点。
它们都是集中封装了对象的创建,使得要更换对象时,不需要做大的改动就可实现,降低了客户程序与产品对象的耦合。工厂方法模式是简单工厂模式的进一步抽象和推广。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。但缺点是由于每加一个产品,就需要加一个产品工厂的类,增加了额外的开发量。而利用‘反射’可以解决避免分支判断的问题
3.1.4 原型模式
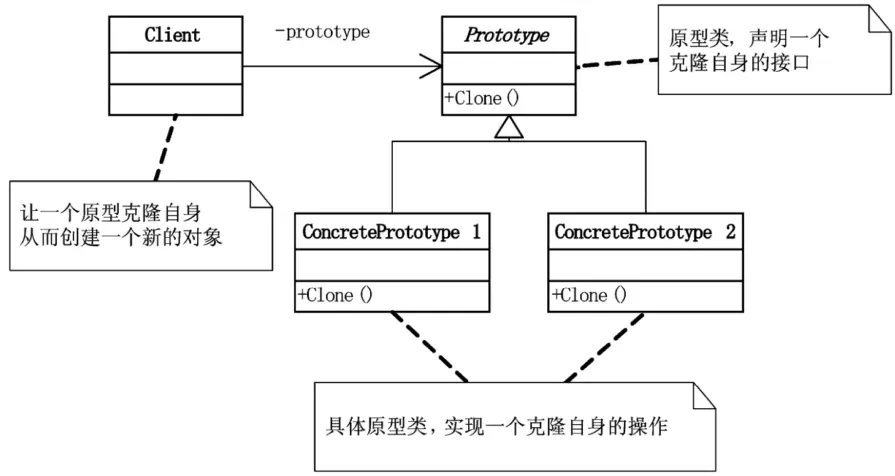
对编程来说,简单的复制粘贴极有可能造成重复代码的灾难。
原型模式(Prototype),用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
原型模式其实就是从一个对象再创建另外一个可定制的对象,而且不需知道任何创建的细节。
原型模式因为需要经常拷贝,所以不需要定义
3.1.5 单例模式

单例模式(Singleton),保证一个类仅有一个实例,并提供一个访问它的全局访问点。
通常我们可以让一个全局变量使得一个对象被访问,但它不能防止你实例化多个对象。一个最好的办法就是,让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,并且它可以提供一个访问该实例的方法。
单例模式除了可以保证唯一的实例外,还有其他好处,式因为Singleton类封装它的唯一实例,这样它可以严格地控制客户怎样访问它以及何时访问它。简单地说就是对唯一实例的受控访问。
其他细节:多线程的程序中,多个线程同时,注意是同时访问Singleton类,调用GetInstance()方法,会有可能造成创建多个实例的。可以给进程一把锁来处理。这里需要解释一下lock语句的涵义,lock是确保当一个线程位于代码的临界区时,另一个线程不进入临界区。如果其他线程试图进入锁定的代码,则它将一直等待(即被阻止),直到该对象被释放。#但这样就得每次调用GetInstance方法时都需要lock,这种做法是会影响性能的,所以对这个类再做改良。
我们不用让线程每次都加锁,而只是在实例未被创建的时候再加锁处理。同时也能保证多线程的安全。这种做法被称为Double-Check Locking(双重锁定)。
静态初始化的方式是在自己被加载时就将自己实例化,所以被形象地称之为饿汉式单例类,原先的单例模式处理方式是要在第一次被引用时,才会将自己实例化,所以就被称为懒汉式单例类。
由于饿汉式,即静态初始化的方式,它是类一加载就实例化的对象,所以要提前占用系统资源。然而懒汉式,又会面临着多线程访问的安全性问题,需要做双重锁定这样的处理才可以保证安全。所以到底使用哪一种方式,取决于实际的需求。
3.2 结构型模式
3.2.1 适配器模式
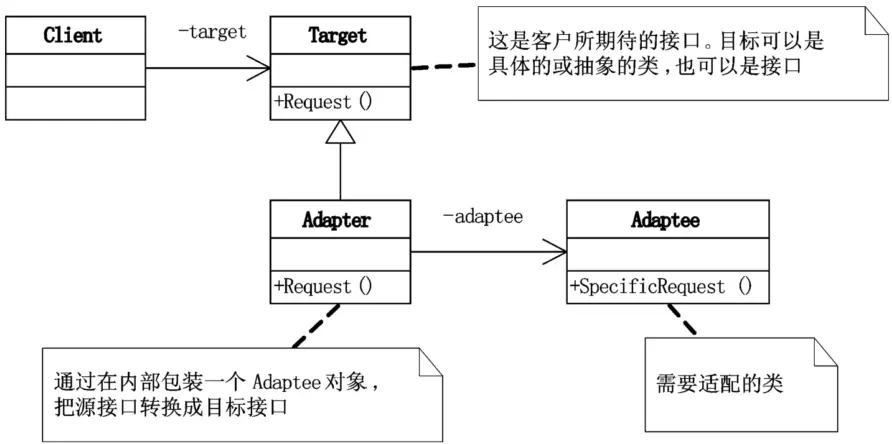
适配器模式(Adapter),将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
适配器模式主要解决什么问题呢?简单地说,就是需要的东西就在面前,但却不能使用,而短时间又无法改造它,于是我们就想办法适配它。
软件开发中,也就是系统的数据和行为都正确,但接口不符时,我们应该考虑用适配器,目的是使控制范围之外的一个原有对象与某个接口匹配。适配器模式主要应用于希望复用一些现存的类,但是接口又与复用环境要求不一致的情况,比如在需要对早期代码复用一些功能等应用上很有实际价值。
在GoF的设计模式中,对适配器模式讲了两种类型,类适配器模式和对象适配器模式,由于类适配器模式通过多重继承对一个接口与另一个接口进行匹配,而C#、VB.NET、JAVA等语言都不支持多重继承(C++支持),也就是一个类只有一个父类,所以我们这里主要讲的是对象适配器。
想使用一个已经存在的类,但如果它的接口,也就是它的方法和你的要求不相同时,就应该考虑用适配器模式。两个类所做的事情相同或相似,但是具有不同的接口时要使用它。客户代码可以统一调用同一接口就行了,这样应该可以更简单、更直接、更紧凑。
其实用适配器模式也是无奈之举,很有点‘亡羊补牢’的感觉,没办法呀,是软件就有维护的一天,维护就有可能会因不同的开发人员、不同的产品、不同的厂家而造成功能类似而接口不同的情况,此时就是适配器模式大展拳脚的时候了。
最好前期就设计好,然后如果真的如你所说,接口不相同时,首先不应该考虑用适配器,而是应该考虑通过重构统一接口。
在双方都不太容易修改的时候再使用适配器模式适配,而不是一有不同时就使用它。
适配器模式当然是好模式,但如果无视它的应用场合而盲目使用,其实是本末倒置了。
3.2.2 桥接模式
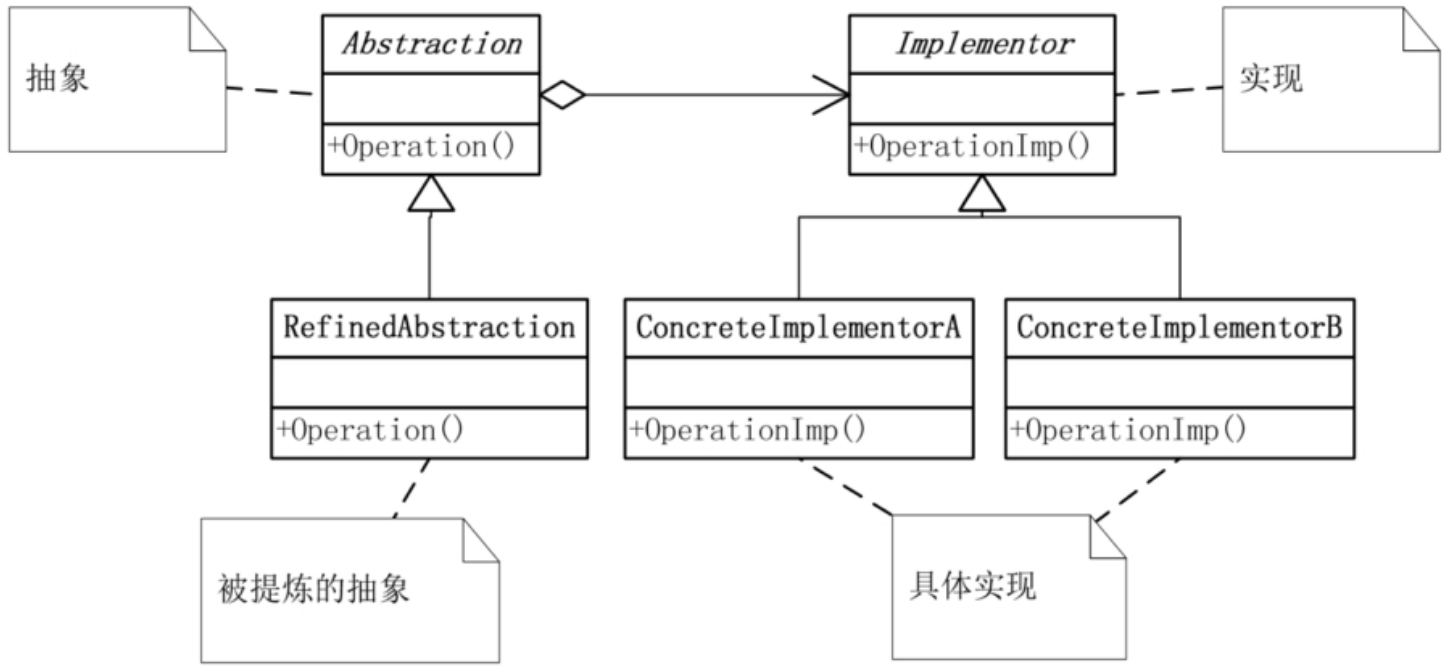
刚开始学会用面向对象的继承时,感觉它既新颖又功能强大,所以只要可以用,就都用上继承。这就好比是‘有了新锤子,所有的东西看上去都成了钉子。但事实上,很多情况用继承会带来麻烦。比如,对象的继承关系是在编译时就定义好了,所以无法在运行时改变从父类继承的实现。子类的实现与它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化。当你需要复用子类时,如果继承下来的实现不适合解决新的问题,则父类必须重写或被其他更适合的类替换。这种依赖关系限制了灵活性并最终限制了复用性。
桥接模式(Bridge),将抽象部分与它的实现部分分离,使它们都可以独立地变化。
什么叫抽象与它的实现分离,这并不是说,让抽象类与其派生类分离,因为这没有任何意义。实现指的是抽象类和它的派生类用来实现自己的对象。就刚才的例子而言,就是让‘手机’既可以按照品牌来分类,也可以按照功能来分类。
由于实现的方式有多种,桥接模式的核心意图就是把这些实现独立出来,让它们各自地变化。这就使得每种实现的变化不会影响其他实现,从而达到应对变化的目的。
实现系统可能有多角度分类,每一种分类都有可能变化,那么就把这种多角度分离出来让它们独立变化,减少它们之间的耦合。
在发现我们需要多角度去分类实现对象,而只用继承会造成大量的类增加,不能满足开放-封闭原则时,就应该要考虑用桥接模式了。
3.2.3 组合模式
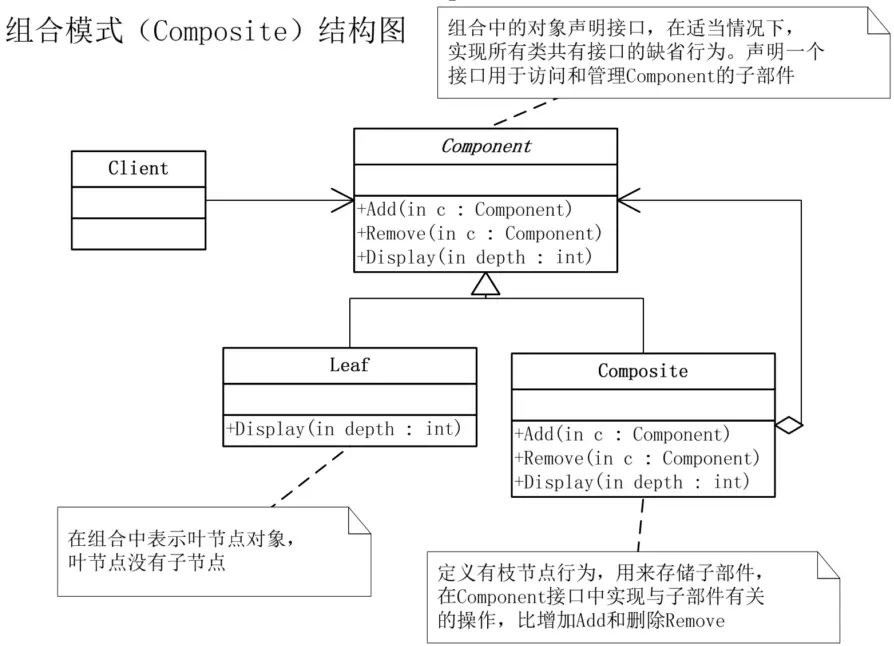
组合模式(Composite),将对象组合成树形结构以表示‘部分-整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
Component为组合中的对象声明接口,在适当情况下,实现所有类共有接口的默认行为。声明一个接口用于访问和管理Component的子部件。
Leaf在组合中表示叶节点对象,叶节点没有子节点。
Composite定义有枝节点行为,用来存储子部件,在Component接口中实现与子部件有关的操作,比如增加Add和删除Remove。
Leaf类当中也有Add和Remove,树叶不是不可以再长分枝吗?这种方式叫做透明方式,也就是说在Component中声明所有用来管理子对象的方法,其中包括Add、Remove等。这样做的好处就是叶节点和枝节点对于外界没有区别,它们具备完全一致的行为接口。但问题也很明显,因为Leaf类本身不具备Add()、Remove()方法的功能,所以实现它是没有意义的。那样就不用做任何判断了。
如果不希望做这样的无用功呢?也就是Leaf类当中不用Add和Remove方法,也是可以的。那么就需要安全方式,也就是在Component接口中不去声明Add和Remove方法,那么子类的Leaf也就不需要去实现它,而是在Composite声明所有用来管理子类对象的方法,这样做就不会出现刚才提到的问题,不过由于不够透明,所以树叶和树枝类将不具有相同的接口,客户端的调用需要做相应的判断,带来了不便。
当你发现需求中是体现部分与整体层次的结构时,以及你希望用户可以忽略组合对象与单个对象的不同,统一地使用组合结构中的所有对象时,就应该考虑用组合模式了。
组合模式这样就定义了包含组合对象的类层次结构。基本对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断地递归下去,客户代码中,任何用到基本对象的地方都可以使用组合对象了。
用户是不用关心到底是处理一个叶节点还是处理一个组合组件,也就用不着为定义组合而写一些选择判断语句了。组合模式让客户可以一致地使用组合结构和单个对象。
3.2.4 装饰模式
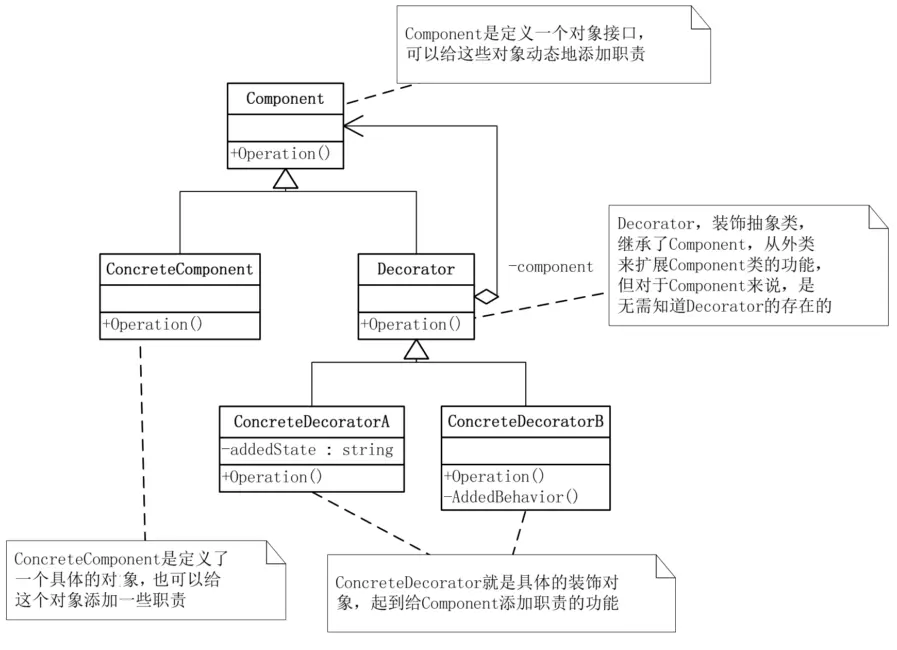
装饰模式(Decorator),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为灵活。
装饰模式是利用SetComponent来对对象进行包装的。这样每个装饰对象的实现就和如何使用这个对象分离开了,每个装饰对象只关心自己的功能,不需要关心如何被添加到对象链当中
装饰模式是为已有功能动态地添加更多功能的一种方式,一次只增加一种功能,顺序可以自由改变。
当系统需要新功能的时候,是向旧的类中添加新的代码。这些新加的代码通常装饰了原有类的核心职责或主要行为,但这种做法的问题在于,它们在主类中加入了新的字段,新的方法和新的逻辑,从而增加了主类的复杂度,而这些新加入的东西仅仅是为了满足一些只在某种特定情况下才会执行的特殊行为的需要。而装饰模式却提供了一个非常好的解决方案,它把每个要装饰的功能放在单独的类中,并让这个类包装它所要装饰的对象,因此,当需要执行特殊行为时,客户代码就可以在运行时根据需要有选择地、按顺序地使用装饰功能包装对象了。
装饰模式的优点是,把类中的装饰功能从类中搬移去除,这样可以简化原有的类。
但是装饰模式的装饰顺序很重要,比如加密数据和过滤词汇都可以是数据持久化前的装饰功能,但若先加密了数据再用过滤功能就会出问题了,最理想的情况,是保证装饰类之间彼此独立,这样它们就可以以任意的顺序进行组合了。
3.2.5 外观模式
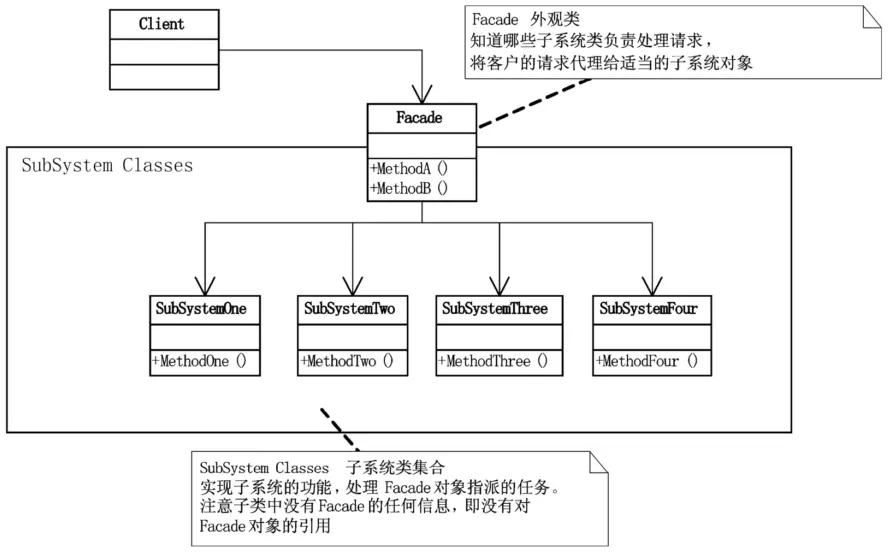
外观模式(Facade),为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
它完美地体现了依赖倒转原则和迪米特法则的思想,所以是非常常用的模式之一。
外观模式在什么时候使用最好呢?
首先,在设计初期阶段,应该要有意识的将不同的两个层分离。比如经典的三层架构,就需要考虑在数据访问层和业务逻辑层、业务逻辑层和表示层的层与层之间建立外观Facade,这样可以为复杂的子系统提供一个简单的接口,使得耦合大大降低。其次,在开发阶段,子系统往往因为不断的重构演化而变得越来越复杂,大多数的模式使用时也都会产生很多很小的类,这本是好事,但也给外部调用它们的用户程序带来了使用上的困难,增加外观Facade可以提供一个简单的接口,减少它们之间的依赖。
第三,在维护一个遗留的大型系统时,可能这个系统已经非常难以维护和扩展了,但因为它包含非常重要的功能,新的需求开发必须要依赖于它。此时用外观模式Facade也是非常合适的。你可以为新系统开发一个外观Facade类,来提供设计粗糙或高度复杂的遗留代码的比较清晰简单的接口,让新系统与Facade对象交互,Facade与遗留代码交互所有复杂的工作。
对于复杂难以维护的老系统,直接去改或去扩展都可能产生很多问题,分两个小组,一个开发Facade与老系统的交互,另一个只要了解Facade的接口,直接开发新系统调用这些接口即可,确实可以减少很多不必要的麻烦。
3.2.6 享元模式
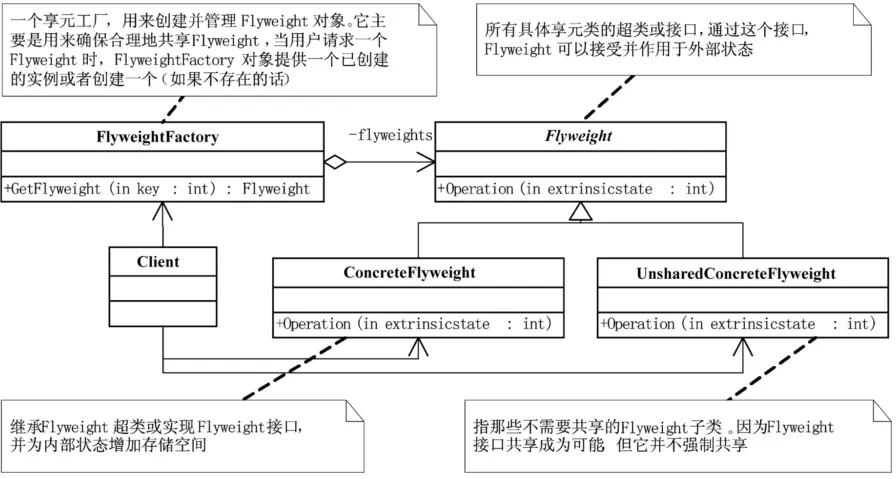
享元模式(Flyweight),运用共享技术有效地支持大量细粒度的对象。在享元对象内部并且不会随环境改变而改变的共享部分,可以称为是享元对象的内部状态,而随环境改变而改变的、不可以共享的状态就是外部状态了。事实上,享元模式可以避免大量非常相似类的开销。在程序设计中,有时需要生成大量细粒度的类实例来表示数据。如果能发现这些实例除了几个参数外基本上都是相同的,有时就能够受大幅度地减少需要实例化的类的数量。如果能把那些参数移到类实例的外面,在方法调用时将它们传递进来,就可以通过共享大幅度地减少单个实例的数目。也就是说,享元模式Flyweight执行时所需的状态是有内部的也可能有外部的,内部状态存储于ConcreteFlyweight对象之中,而外部对象则应该考虑由客户端对象存储或计算,当调用Flyweight对象的操作时,将该状态传递给它。
如果一个应用程序使用了大量的对象,而大量的这些对象造成了很大的存储开销时就应该考虑使用;还有就是对象的大多数状态可以外部状态,如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象,此时可以考虑使用享元模式。
因为用了享元模式,所以有了共享对象,实例总数就大大减少了,如果共享的对象越多,存储节约也就越多,节约量随着共享状态的增多而增大。
在某些情况下,对象的数量可能会太多,从而导致了运行时的资源与性能损耗。那么我们如何去避免大量细粒度的对象,同时又不影响客户程序,是一个值得去思考的问题,享元模式,可以运用共享技术有效地支持大量细粒度的对象。不过,你也别高兴得太早,使用享元模式需要维护一个记录了系统已有的所有享元的列表,而这本身需要耗费资源,另外享元模式使得系统更加复杂。为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化。因此,应当在有足够多的对象实例可供共享时才值得使用享元模式。
3.2.7 代理模式
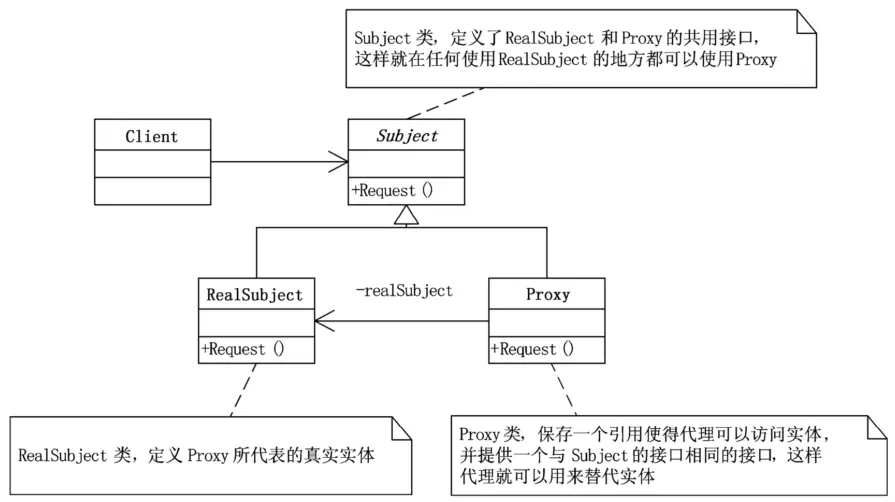
代理模式(Proxy),为其他对象提供一种代理以控制对这个对象的访问。
代理模式用在以下几种场景,第一,远程代理,也就是为一个对象在不同的地址空间提供局部代表。这样可以隐藏一个对象存在于不同地址空间的事实。
第二种应用是虚拟代理,是根据需要创建开销很大的对象。通过它来存放实例化需要很长时间的真实对象。这样就可以达到性能的最优化,比如说你打开一个很大的HTML网页时,里面可能有很多的文字和图片,但你还是可以很快打开它,此时你所看到的是所有的文字,但图片却是一张一张地下载后才能看到。那些未打开的图片框,就是通过虚拟代理来替代了真实的图片,此时代理存储了真实图片的路径和尺寸。
第三种应用是安全代理,用来控制真实对象访问时的权限。一般用于对象应该有不同的访问权限的时候。
第四种是智能指引,是指当调用真实的对象时,代理处理另外一些事[DP]。如计算真实对象的引用次数,这样当该对象没有引用时,可以自动释放它;或当第一次引用一个持久对象时,将它装入内存;或在访问一个实际对象前,检查是否已经锁定它,以确保其他对象不能改变它。它们都是通过代理在访问一个对象时附加一些内务处理。
代理模式其实就是在访问对象时引入一定程度的间接性,因为这种间接性,可以附加多种用途。
3.3 行为型模式
3.3.1 策略模式
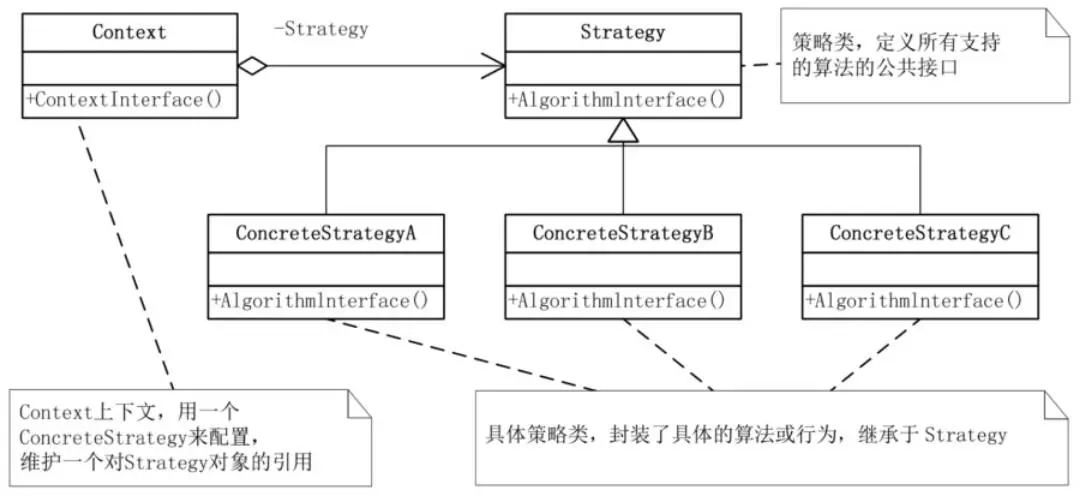
策略模式定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化,不会影响到使用算法的客户。
对于商场收银时如何促销,用打折还是返利,其实都是一些算法,用工厂来生成算法对象,这没有错,但算法本身只是一种策略,最重要的是这些算法是随时都可能互相替换的,这就是变化点,而封装变化点是我们面向对象的一种很重要的思维方式。
策略模式是一种定义一系列算法的方法,从概念上来看,所有这些算法完成的都是相同的工作,只是实现不同,它可以以相同的方式调用所有的算法,减少了各种算法类与使用算法类之间的耦合。继承有助于析取出这些算法中的公共功能
策略模式的另一个优点是简化了单元测试,因为每个算法都有自己的类,可以通过自己的接口单独测试
当不同的行为堆砌在一个类中时,就很难避免使用条件语句来选择合适的行为。将这些行为封装在一个个独立的Strategy类中,可以在使用这些行为的类中消除条件语句。策略模式就是用来封装算法的,但在实践中,我们发现可以用它来封装几乎任何类型的规则,只要在分析过程中听到需要在不同时间应用不同的业务规则,就可以考虑使用策略模式处理这种变化的可能性。
但如果我们需要增加一种算法,你就必须要更改策略类中的条件判断代码,还是有一定成本的。
区别:
简单工厂模式关注点是返回实例化对象,然后这个对象去执行某些事。
策略模式关注点是返回一个“策略清单”,然后按照清单去执行某些事。
3.3.2 模板方法模式
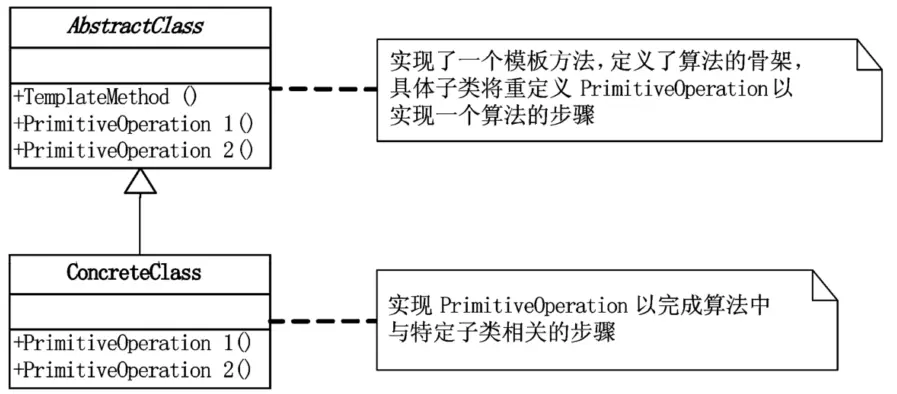
既然用了继承,并且肯定这个继承有意义,就应该要成为子类的模板,所有重复的代码都应该要上升到父类去,而不是让每个子类都去重复。模板方法就登场了,当我们要完成在某一细节层次一致的一个过程或一系列步骤,但其个别步骤在更详细的层次上的实现可能不同时,我们通常考虑用模板方法模式来处理。
模板方法模式,定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
抽象类,其实也就是一抽象模板,定义并实现了一个模版方法。这个模版方法一般是一个具体方法,它给出了一个顶级逻辑的骨架,而逻辑的组成步骤在相应的抽象操作中,推迟到子类实现。顶级逻辑也有可能调用一些具体方法。
实现父类所定义的一个或多个抽象方法。每一个抽象类都可以有任意多个具体子类与之对应,而每一个具体子类都可以给出这些抽象方法(也就是顶级逻辑的组成步骤)的不同实现,从而使得顶级逻辑的实现各不相同。
模板方法模式是通过把不变行为搬移到超类,去除子类中的重复代码来体现它的优势。
模板方法模式就是提供了一个很好的代码复用平台。因为有时候,我们会遇到由一系列步骤构成的过程需要执行。这个过程从高层次上看是相同的,但有些步骤的实现可能不同。这时候,我们通常就应该要考虑用模板方法模式了。
当不变的和可变的行为在方法的子类实现中混合在一起的时候,不变的行为就会在子类中重复出现。我们通过模板方法模式把这些行为搬移到单一的地方,这样就帮助子类摆脱重复的不变行为的纠缠。
模板方法模式是很常用的模式,对继承和多态玩得好的人几乎都会在继承体系中多多少少用到它。在类的设计中通常都会利用模板方法模式提取类库中的公共行为到抽象类中。
3.3.3 观察者模式
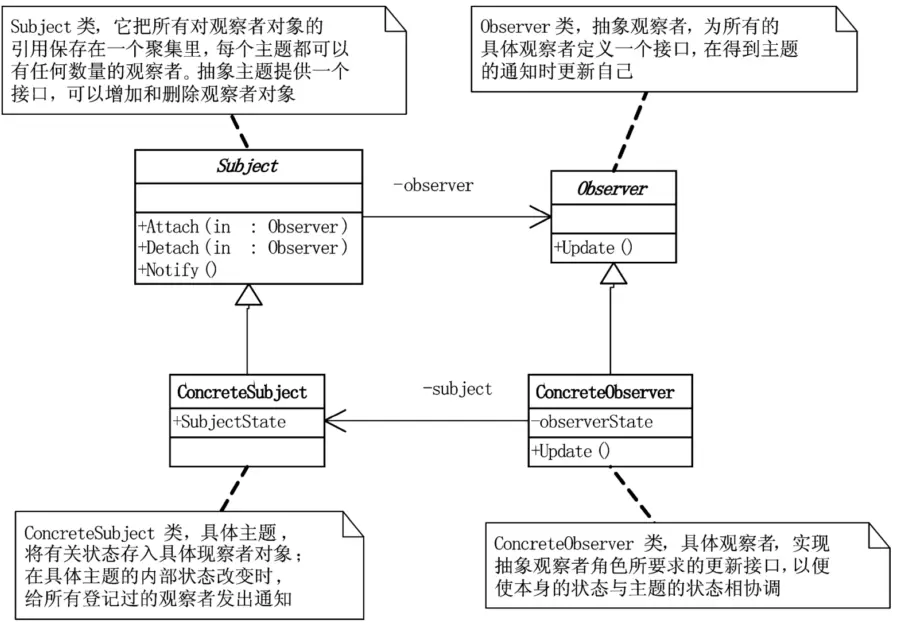
观察者模式又叫做发布-订阅(Publish/Subscribe)模式。
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己。
Subject类,可翻译为主题或抽象通知者,一般用一个抽象类或者一个接口实现。它把所有对观察者对象的引用保存在一个聚集里,每个主题都可以有任何数量的观察者。抽象主题提供一个接口,可以增加和删除观察者对象。
Observer类,抽象观察者,为所有的具体观察者定义一个接口,在得到主题的通知时更新自己。这个接口叫做更新接口。抽象观察者一般用一个抽象类或者一个接口实现。更新接口通常包含一个Update()方法,这个方法叫做更新方法。
ConcreteSubject类,叫做具体主题或具体通知者,将有关状态存入具体观察者对象;在具体主题的内部状态改变时,给所有登记过的观察者发出通知。具体主题角色通常用一个具体子类实现。
ConcreteSubject类,叫做具体主题或具体通知者,将有关状态存入具体观察者对象;在具体主题的内部状态改变时,给所有登记过的观察者发出通知。具体主题角色通常用一个具体子类实现。
观察者模式的动机是将一个系统分割成一系列相互协作的类有一个很不好的副作用,那就是需要维护相关对象间的一致性。我们不希望为了维持一致性而使各类紧密耦合,这样会给维护、扩展和重用都带来不便[DP]。而观察者模式的关键对象是主题Subject和观察者Observer,一个Subject可以有任意数目的依赖它的Observer,一旦Subject的状态发生了改变,所有的Observer都可以得到通知。Subject发出通知时并不需要知道谁是它的观察者,也就是说,具体观察者是谁,它根本不需要知道。而任何一个具体观察者不知道也不需要知道其他观察者的存在。
什么时候应该使用?当一个对象的改变需要同时改变其他对象的时候,而且它不知道具体有多少对象有待改变时,应该考虑使用观察者模式。另外,当一个抽象模型有两个方面,其中一方面依赖于另一方面,这时用观察者模式可以将这两者封装在独立的对象中使它们各自独立地改变和复用。
观察者模式所做的工作其实就是在解除耦合。让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响另一边的变化。
已经用了依赖倒转原则,但是‘抽象通知者’还是依赖‘抽象观察者’,也就是说,万一没有了抽象观察者这样的接口,我这通知的功能就完不成了。另外就是每个具体观察者,它不一定是‘更新’的方法要调用呀,就像刚才说的,我希望的是‘工具箱’是隐藏,‘自动窗口’是打开,这根本就不是同名的方法。这应该就是不足的地方。如果通知者和观察者之间根本就互相不知道,由客户端来决定通知谁,那就好了。不需要抽象观察者。
可以用一个非常好的技术来处理这个问题,它叫委托。通知者和观察者之间的通知可以使用委托来传递(解决了有的观察者被通知,有的观察者不被通知的问题),名称叫“EventHandler(事件处理程序)”,无参数,无返回值。
委托就是一种引用方法的类型。一旦为委托分配了方法,委托将与该方法具有完全相同的行为。委托方法的使用可以像其他任何方法一样,具有参数和返回值。委托可以看作是对函数的抽象,是函数的‘类’,委托的实例将代表一个具体的函数。
一旦为委托分配了方法,委托将与该方法具有完全相同的行为。而且,一个委托可以搭载多个方法,所有方法被依次唤起。更重要的是,它可以使得委托对象所搭载的方法并不需要属于同一个类。
但委托也是有前提的,那就是委托对象所搭载的所有方法必须具有相同的原形和形式,也就是拥有相同的参数列表和返回值类型。
3.3.4 抽象工厂模式
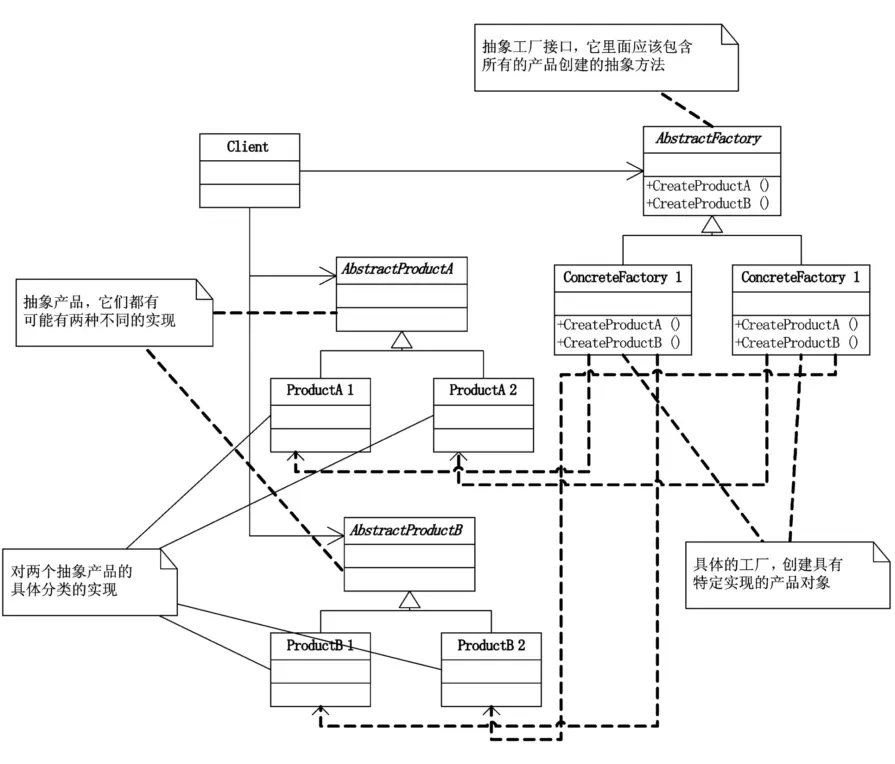
只有一个User类和User操作类的时候,是只需要工厂方法模式的,但现在显然你数据库中有很多的表,而SQL Server与Access又是两大不同的分类,所以解决这种涉及到多个产品系列的问题,有一个专门的工厂模式叫抽象工厂模式。
抽象工厂模式(Abstract Factory),提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
通常是在运行时刻再创建一个ConcreteFactory类的实例,这个具体的工厂再创建具有特定实现的产品对象,也就是说,为创建不同的产品对象,客户端应使用不同的具体工厂。
这样做的最大的好处便是易于交换产品系列,使得改变一个应用的具体工厂变得非常容易,它只需要改变具体工厂即可使用不同的产品配置。我们的设计不能去防止需求的更改,那么我们的理想便是让改动变得最小,第二大好处是,它让具体的创建实例过程与客户端分离,客户端是通过它们的抽象接口操纵实例,产品的具体类名也被具体工厂的实现分离,不会出现在客户代码中。
如果你的需求来自增加功能,比如我们现在要增加项目表Project,客户端程序类显然不会是只有一个,有很多地方都在使用IUser或IDepartment,而这样的设计,其实在每一个类的开始都需要声明IFactory factory = new SqlserverFactory(),如果我有100个调用数据库访问的类,是不是就要更改100次IFactory factory = new AccessFactory()这样的代码才行?这不能解决我要更改数据库访问时,改动一处就完全更改的要求呀!
可以改用简单工厂模式,但是多加需求switch都要改,可以用依赖注入,依赖注入(Dependency Injection)。关键在于如何去用这种方法来解决我们的switch问题
在反射中‘CreateInstance(“抽象工厂模式. SqlserverUser”)’,可以灵活更换‘SqlserverUser’为‘AccessUser’。因为这里是字符串,可以用变量来处理,也就可以根据需要更换。
还可以利用配置文件来解决更改DataAccess的问题。可以读文件来给DB字符串赋值,在配置文件中写明是Sqlserver还是Access,这样就连DataAccess类也不用更改了。于是就应用了反射+抽象工厂模式解决了数据库访问时的可维护、可扩展的问题。
3.3.5 状态模式
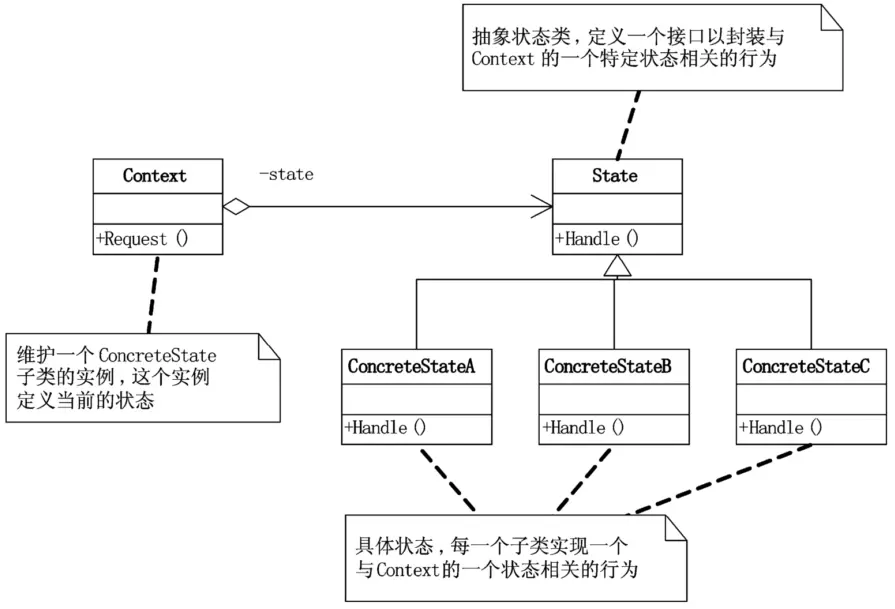
面向对象设计其实就是希望做到代码的责任分解。状态模式(State),当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类。
状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化
状态模式和策略模式差不多。区别在于状态模式中的 ConcreteState 需要知道其他 ConcreteState 的存在,因为要设置下一步的 ConcreteState。
ConcreteState类,具体状态,每一个子类实现一个与Context的一个状态相关的行为。
状态模式的好处是将与特定状态相关的行为局部化,并且将不同状态的行为分割开来。将特定的状态相关的行为都放入一个对象中,由于所有与状态相关的代码都存在于某个ConcreteState中,所以通过定义新的子类可以很容易地增加新的状态和转换
这样做的目的就是为了消除庞大的条件分支语句,大的分支判断会使得它们难以修改和扩展,就像我们最早说的刻版印刷一样,任何改动和变化都是致命的。状态模式通过把各种状态转移逻辑分布到State的子类之间,来减少相互间的依赖,好比把整个版面改成了一个又一个的活字,此时就容易维护和扩展了。
什么时候应该考虑使用状态模式呢?当一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为时,就可以考虑使用状态模式了。
如果业务需求某项业务有多个状态,通常都是一些枚举常量,状态的变化都是依靠大量的多分支判断语句来实现,此时应该考虑将每一种业务状态定义为一个State的子类。这样这些对象就可以不依赖于其他对象而独立变化了,某一天客户需要更改需求,增加或减少业务状态或改变状态流程,对你来说都是不困难的事。
3.3.6 备忘录模式
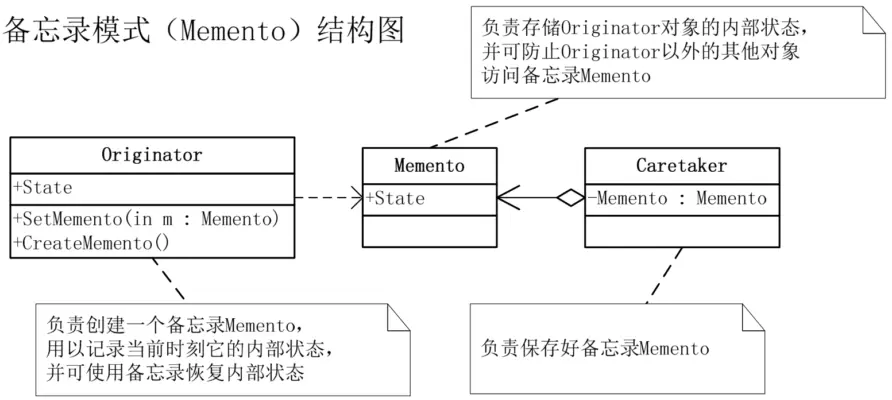
备忘录(Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
Originator(发起人):负责创建一个备忘录Memento,用以记录当前时刻它的内部状态,并可使用备忘录恢复内部状态。Originator可根据需要决定Memento存储Originator的哪些内部状态。
Memento(备忘录):负责存储Originator对象的内部状态,并可防止Originator以外的其他对象访问备忘录Memento。备忘录有两个接口,Caretaker只能看到备忘录的窄接口,它只能将备忘录传递给其他对象。Originator能够看到一个宽接口,允许它访问返回到先前状态所需的所有数据。
Caretaker(管理者):负责保存好备忘录Memento,不能对备忘录的内容进行操作或检查。
把要保存的细节给封装在了Memento中了,哪一天要更改保存的细节也不用影响客户端了。
emento模式比较适用于功能比较复杂的,但需要维护或记录属性历史的类,或者需要保存的属性只是众多属性中的一小部分时,Originator可以根据保存的Memento信息还原到前一状态。
如果在某个系统中使用命令模式时,需要实现命令的撤销功能,那么命令模式可以使用备忘录模式来存储可撤销操作的状态。有时一些对象的内部信息必须保存在对象以外的地方,但是必须要由对象自己读取,这时,使用备忘录可以把复杂的对象内部信息对其他的对象屏蔽起来。从而可以恰当地保持封装的边界。
最大的作用还是在当角色的状态改变的时候,有可能这个状态无效,这时候就可以使用暂时存储起来的备忘录将状态复原。
备忘录模式也是有缺点的,角色状态需要完整存储到备忘录对象中,如果状态数据很大很多,那么在资源消耗上,备忘录对象会非常耗内存。
3.3.7 迭代器模式
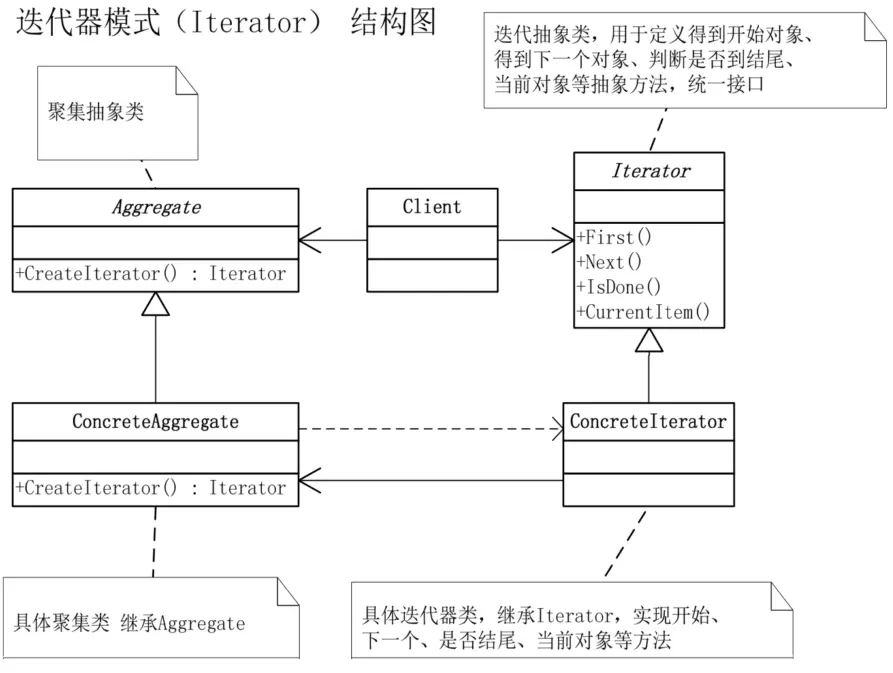
迭代器模式(Iterator),提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。
当你需要访问一个聚集对象,而且不管这些对象是什么都需要遍历的时候,你就应该考虑用迭代器模式。为遍历不同的聚集结构提供如开始、下一个、是否结束、当前哪一项等统一的接口。
为什么要用具体的迭代器ConcreteIterator来实现抽象的Iterator呢?我感觉这里不需要抽象呀,直接访问ConcreteIterator不是更好吗?
当你需要对聚集有多种方式遍历时,可以考虑用迭代器模式,事实上,售票员一定要从车头到车尾这样售票吗?
尽管我们不需要显式的引用迭代器,但系统本身还是通过迭代器来实现遍历的。总地来说,迭代器(Iterator)模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。迭代器模式在访问数组、集合、列表等数据时,尤其是数据库数据操作时,是非常普遍的应用,但由于它太普遍了,所以各种高级语言都对它进行了封装,所以反而给人感觉此模式本身不太常用了。
3.3.8 命令模式
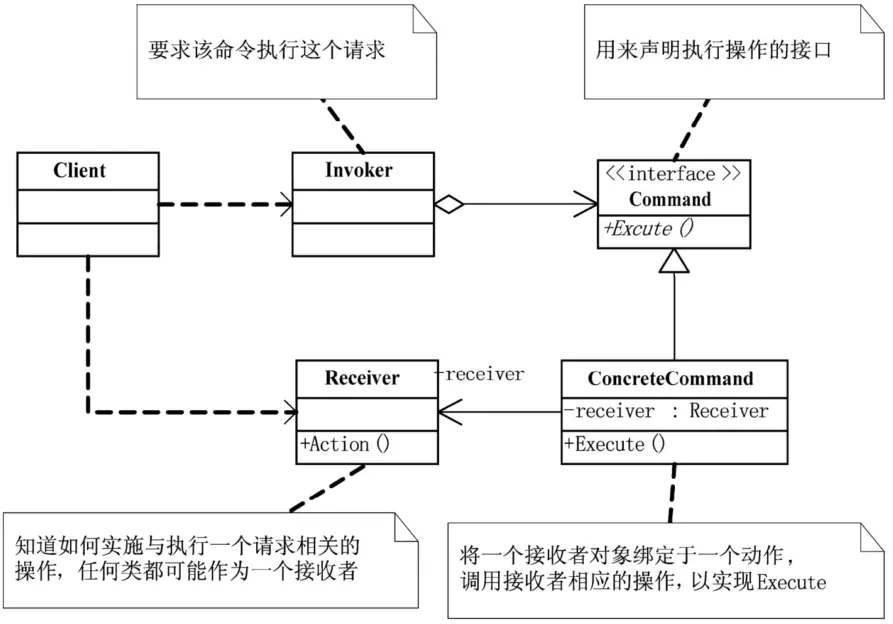
命令模式(Command),将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。
它的优点是:第一,它能较容易地设计一个命令队列;第二,在需要的情况下,可以较容易地将命令记入日志;第三,允许接收请求的一方决定是否要否决请求。第四,可以容易地实现对请求的撤销和重做;第五,由于加进新的具体命令类不影响其他的类,因此增加新的具体命令类很容易。其实还有最关键的优点就是命令模式把请求一个操作的对象与知道怎么执行一个操作的对象分割开。
碰到类似情况也不一定要实现命令模式,比如命令模式支持撤销/恢复操作功能,但你还不清楚是否需要这个功能时,要不要实现?。敏捷开发原则告诉我们,不要为代码添加基于猜测的、实际不需要的功能。如果不清楚一个系统是否需要命令模式,一般就不要着急去实现它,事实上,在需要的时候通过重构实现这个模式并不困难,只有在真正需要如撤销/恢复操作等功能时,把原来的代码重构为命令模式才有意义。
3.3.9 指责链模式
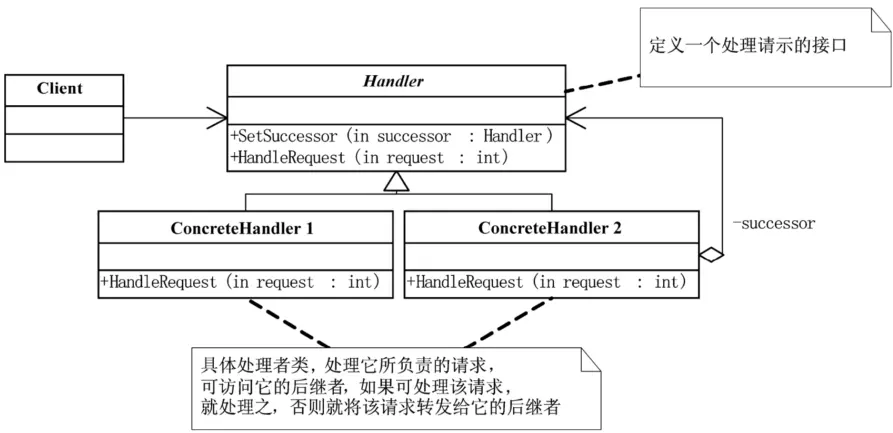
指责链模式(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这个对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
当客户提交一个请求时,请求是沿链传递直至有一个ConcreteHandler对象负责处理它。这就使得接收者和发送者都没有对方的明确信息,且链中的对象自己也并不知道链的结构。结果是职责链可简化对象的相互连接,它们仅需保持一个指向其后继者的引用,而不需保持它所有的候选接受者的引用。这也就大大降低了耦合度了。
这的确是很灵活,不过也要当心,一个请求极有可能到了链的末端都得不到处理,或者因为没有正确配置而得不到处理,这就很糟糕了。需要事先考虑全面。
最重要的有两点,一个是你需要事先给每个具体管理者设置他的上司是哪个类,也就是设置后继者。另一点是你需要在每个具体管理者处理请求时,做出判断,是可以处理这个请求,还是必须要‘推卸责任’,转移给后继者去处理。
3.3.10 中介者模式
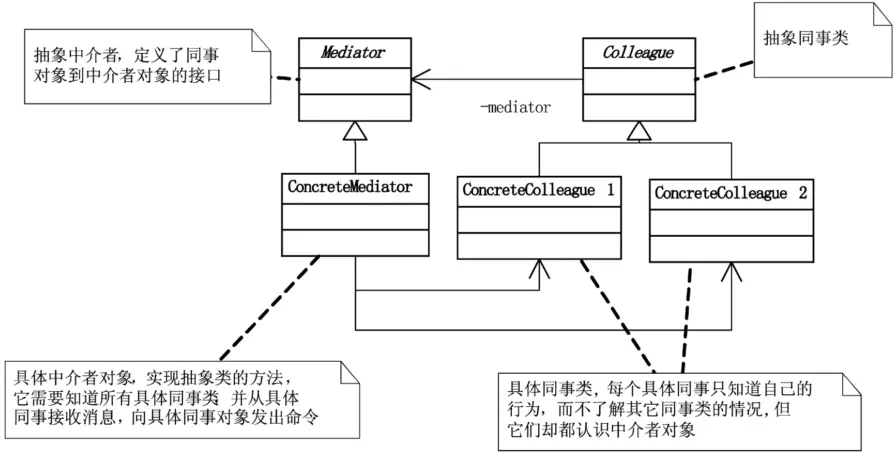
对象之间需要知道其他所有对象,尽管将一个系统分割成许多对象通常可以增加其可复用性,但是对象间相互连接的激增又会降低其可复用性了。大量的连接使得一个对象不可能在没有其他对象的支持下工作,系统表现为一个不可分割的整体,所以,对系统的行为进行任何较大的改动就十分困难了。
‘迪米特法则’,如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。通过中介者对象,可以将系统的网状结构变成以中介者为中心的星形结构,每个具体对象不再通过直接的联系与另一个对象发生相互作用,而是通过‘中介者’对象与另一个对象发生相互作用。中介者对象的设计,使得系统的结构不会因为新对象的引入造成大量的修改工作。
中介者模式(Mediator),用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
最关键的问题在于ConcreteMediator这个类必须要知道所有的ConcreteColleague。尽管这样的设计可以减少了ConcreteColleague类之间的耦合,但这又使得ConcreteMediator责任太多了,如果它出了问题,则整个系统都会有问题了。中介者模式很容易在系统中应用,也很容易在系统中误用。当系统出现了‘多对多’交互复杂的对象群时,不要急于使用中介者模式,而要先反思你的系统在设计上是不是合理。
中介者模式的优点首先是Mediator的出现减少了各个Colleague的耦合,使得可以独立地改变和复用各个Colleague类和Mediator,比如任何国家的改变不会影响到其他国家,而只是与安理会发生变化。其次,由于把对象如何协作进行了抽象,将中介作为一个独立的概念并将其封装在一个对象中,这样关注的对象就从对象各自本身的行为转移到它们之间的交互上来,也就是站在一个更宏观的角度去看待系统。
中介者模式的缺点是具体中介者类ConcreteMediator可能会因为ConcreteColleague的越来越多,而变得非常复杂,反而不容易维护了。
由于ConcreteMediator控制了集中化,于是就把交互复杂性变为了中介者的复杂性,这就使得中介者会变得比任何一个ConcreteColleague都复杂。中介者模式一般应用于一组对象以定义良好但是复杂的方式进行通信的场合,比如刚才得到的窗体Form对象或Web页面aspx,以及想定制一个分布在多个类中的行为,而又不想生成太多的子类的场合。
3.3.11 解释器模式
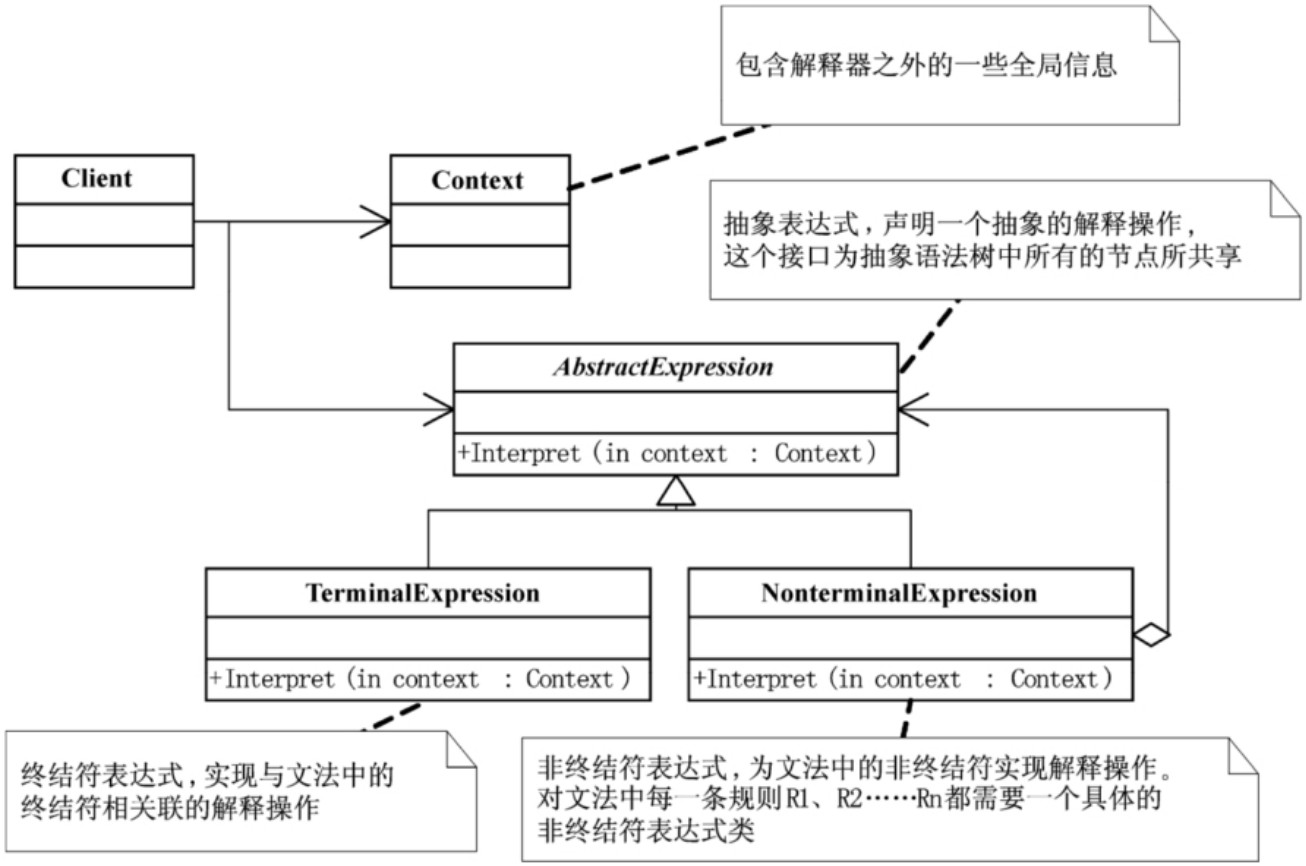
解释器模式(interpreter),给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
解释器模式需要解决的是,如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。比方说,我们常常会在字符串中搜索匹配的字符或判断一个字符串是否符合我们规定的格式,此时一般我们会用什么技术?答案是正则表达式。这个匹配字符的需求在软件的很多地方都会使用,而且行为之间都非常类似,过去的做法是针对特定的需求,编写特定的函数,比如判断Email、匹配电话号码等等,与其为每一个特定需求都写一个算法函数,不如使用一种通用的搜索算法来解释执行一个正则表达式,该正则表达式定义了待匹配字符串的集合。而所谓的解释器模式,正则表达式就是它的一种应用,解释器为正则表达式定义了一个文法,如何表示一个特定的正则表达式,以及如何解释这个正则表达式。
通常当有一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式。用了解释器模式,就意味着可以很容易地改变和扩展文法,因为该模式使用类来表示文法规则,你可使用继承来改变或扩展该文法。也比较容易实现文法,因为定义抽象语法树中各个节点的类的实现大体类似,这些类都易于直接编写。解释器模式也有不足的,解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护。建议当文法非常复杂时,使用其他的技术如语法分析程序或编译器生成器来处
3.3.12 访问者模式
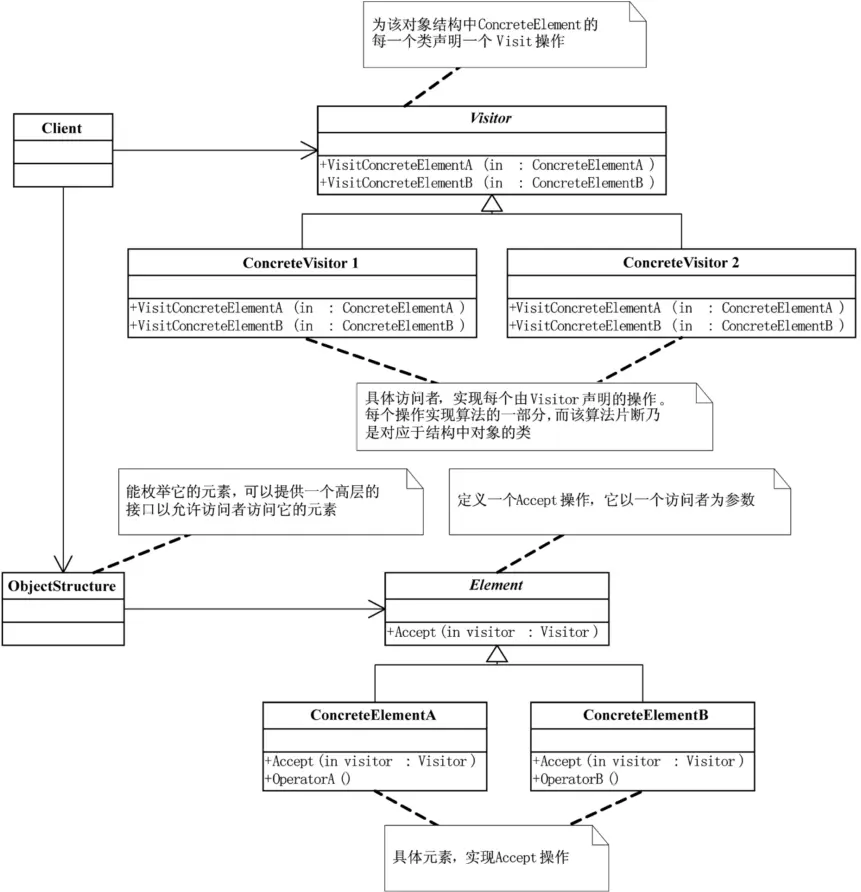
访问者模式讲的是表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
方法个数需要是稳定的,不会很容易的发生变化。如果可有多种类别,那就意味‘状态’类中的抽象方法就不可能稳定了,每加一种类别,就需要在状态类和它的所有下属类中都增加一个方法,这就不符合开放-封闭原则。所以访问者模式适用于数据结构相对稳定的系统。它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由地演化。
访问者模式的目的是要把处理从数据结构分离出来。很多系统可以按照算法和数据结构分开,如果这样的系统有比较稳定的数据结构,又有易于变化的算法的话,使用访问者模式就是比较合适的,因为访问者模式使得算法操作的增加变得容易。反之,如果这样的系统的数据结构对象易于变化,经常要有新的数据对象增加进来,就不适合使用访问者模式。
访问者模式的优点就是增加新的操作很容易,因为增加新的操作就意味着增加一个新的访问者。访问者模式将有关的行为集中到一个访问者对象中。
那访问者的缺点其实也就是使增加新的数据结构变得困难了。
大多时候你并不需要访问者模式,但当一旦你需要访问者模式时,那就是真的需要它了。 事实上,我们很难找到数据结构不变化的情况,所以用访问者模式的机会也就不太多了。
访问者模式的能力和复杂性是把双刃剑,只有当你真正需要它的时候,才考虑使用它。有很多的程序员为了展示自己的面向对象的能力或是沉迷于模式当中,往往会误用这个模式,所以一定要好好理解它的适用性。