《DirectX 12 3D游戏开发实战》阅读笔记1:数学
1. 向量代数
1.1 向量
1.1.1 向量与坐标系
1.1.2 左手坐标系和右手坐标系
1.1.3 向量的基本运算
1.2 长度和单位向量
1.3 点积
1.4 叉积
1.4.1 2D向量的伪叉积
1.4.2 通过叉积来进行正交化处理
1.5 点
1.6 利用DirectXMath库进行向量运
1.6.1 向量类型
-
了解DirectXMath库设计原理,推荐文章《Designing Fast Cross-Platform SIMD Vector Libraries》。
-
使用DirectXMath库(维护人Chuck Walbourn):
1 |
-
平台设置
- x86:可以启用SSE2指令集,x64不需要(CPU已支持)。
- 所有平台,应启用快速浮点模型
/fp:fast
-
核心向量类型:
XMVECTOR,有128位,按16位对齐(自动实现),直接传送到SSE/SSE2寄存器,而不存在于栈内,利用SIMD特性一次可以处理4个32位的浮点数,建议利用于局部变量和全局变量,定义为:
1 | typedef __m128 XMVECTOR; // __m128 定义在xmmintrin.h |
- 类内成员变量一般不用
XMVECTOR类型,建议用XMFLOAT2、XMFLOAT3、XMFLOAT4类型,它们是float类型的结构体。
1. 为什么类内成员变量用的是
XMFLOATn类型?
- 避免不兼容16字节内存对齐:类的成员变量布局受编译器默认对齐规则很难保证
XMVector作为成员时始终满足 16 字节对齐。XMFLOAT2(2 个float,8 字节)、XMFLOAT3(3 个float,12 字节)、XMFLOAT4(4 个float,16 字节)等类型基于标准float,仅需自然对齐(4 字节),可完美融入类的内存布局。- 节省内存开销:
XMFLOATn可节省内存(例如XMFLOAT3比XMVector少 4 字节)。- 数据序列化和兼容性好:
XMFLOATn内存布局清晰(连续的 float 数组),数据序列化与兼容性好,适合持久化存储格式。2.
XMFLOAT2里有一个构造函数是explicit XMFLOAT2(_In_reads_ (2) const float* pArray),这里的_In_reads_ (2)是什么意思?
- 这是微软的代码分析工具(Code Analysis)使用的注解,表示这个参数是一个输入参数,且指向一个包含2个元素的数组。它帮助静态分析工具理解代码意图,进行更准确的检查和警告。这些注解不影响代码的实际运行逻辑,仅用于增强代码的可读性和可维护性,是微软生态中推荐的代码规范。
- 为了充分发挥SIMD的优势,一般先把
XMFLOATn转换为XMVECTOR,进行向量运算后,再转换回XMFLOATn。
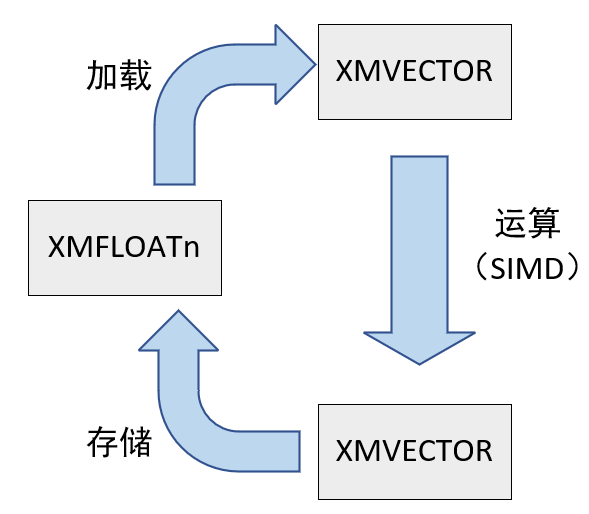
1.6.2 加载方法和存储方法
1.6.3 参数的传递
XM_CALLCONV是 DirectX Math 库中用于指定函数调用约定(calling convention)的宏,主要作用是确保 DirectX 数学函数在不同平台和编译器下采用最优的参数传递方式,尤其是针对 SIMD 类型(如 XMVector)的高效处理。DirectX Math 的许多函数会用到,比如
1 | XMVECTOR XM_CALLCONV XMLoadFloat2(const XMFLOAT2 *pSource); |
1.
FXMVECTOR和XMVECTOR有什么区别?
- 两者的关键差异体现在函数参数传递时的处理逻辑(由
XM_CALLCONV调用约定配合实现):
FXMVECTOR:表示 “快速传递的输入向量”(Fast input Vector)。在支持的平台(如 x64)上,标注为FXMVECTOR的参数会优先通过寄存器传递(而非栈内存),减少内存访问开销,适合作为函数的输入参数。
XMVECTOR:为普通参数时,可能通过栈传递(尤其是在 32 位平台或参数数量较多时)。通常用于函数的返回值、局部变量或输出参数。
例如:
输入参数:用
FXMVECTOR标注,优先通过寄存器传递,提升调用效率。
返回值:用XMVECTOR,函数计算结果通过寄存器返回。
- 函数里传递
XMVECTOR类型的输入参数规则为:前3个参数用FXMVECTOR,第4个参数用GXMVECTOR,第5、6个用HXMVECTOR,其余的XMVECTOR参数用CXMVECTOR。这些类型都是typedef(const XMVECTOR或const XMVECTOR&),编译选项__fastcall和__vectorcall有所不同(见书19页)。对于构造函数有额外的建议:前3个XMVECTOR参数用FXMVECTOR类型,其余XMVECTOR参数用CXMVECTOR类型,不要使用XM_CALLCONV。 - 传递
XMVECTOR参数规则适用于“输入”输入参数,“输出”的XMVECTOR参数不会占有SSE/SSE2寄存器,它们的处理方式和非XMVECTOR类型的参数一致。
1.6.4 常向量
XMVECTOR类型的常量实例用XMVECTORF32(浮点数)或XMVECTORU32(整型)表示,它是按16字节对齐的结构体,使用例子如:
1 | __declspec(align(16)) struct XMVECTORF32 |
1_
XM_NO_INTRINSICS_和_XM_SSE_INTRINSICS是什么宏
_XM_NO_INTRINSICS_含义:禁用硬件 intrinsics( intrinsic 指编译器提供的直接映射硬件指令对应的函数)。
_XM_SSE_INTRINSICS_含义:强制使用 SSE 指令集的 intrinsics 实现。
1.6.5 重载运算符
1.6.6 杂项
1.6.7 Setter函数
1.6.8 向量函数
1.6.9 浮点数误差
2. 矩阵代数
2.1 矩阵的定义
2.2 矩阵乘法
2.2.1 定义
2.2.2 向量与矩阵的乘法
2.2.3 结合律
2.3 转置矩阵
2.4 单位矩阵
2.5 矩阵的行列式
2.5.1 余子式
2.5.2 行列式的定义
2.6 伴随矩阵
2.7 逆矩阵
2.8 用DirectXMath库处理矩阵
- 矩阵核心类型是
XMMATRIX,内部实现是使用4个XMVECTOR表示矩阵。 - 类内矩阵类型数据变量建议使用
XMFLOAT4x4存储。 - 声明传参有
XMMATRIX类型的函数,一个XMMATRIX记作4个XMVECTOR参数,其他的规则和传入XMVECTOR参数是一样的,即第一个XMMATRIX用的是FXMMATRIX,后面的XMMATRIX用的是CXMMATRIX。构造函数建议采用CMMATRIX类型来获取XMMATRIX参数,对于构造函数不要使用XM_CALLCONV约定注解。 __fastcall只支持3个XMVECTOR参数传入,是不能传入SSE/SSE2寄存器的,但是矩阵有4个XMVECTOR,矩阵类型的数据只能通过堆栈来引用。
3. 变换
3.1 线性变换
3.1.1 定义
3.1.2 矩阵表示法
3.1.3 缩放
3.1.4 旋转
3.2 仿射变换
3.2.1 齐次坐标
- 齐次坐标
(x,y,z,w)里w分量为0表示向量,为1表示点。