《游戏引擎架构》笔记5:游戏支持系统
1. 子系统的启动和终止
子系统互相依赖,启动次序很关键,控制次序方案:
1.1 单例全局变量❌️
- 程序进入点(
main()或WinMain())前全局及静态对象构造函数调用次序无法预知 - 程序(
main()或WinMain())结束返回后全局及静态对象析构函数调用次序无法预知 - 因此不能使用单例:单例构建时依赖的单例可能还未构建,单例析构时依赖的单例可能已经析构。
1 | class Manager |
1.2 静态变量按需构建❌️
主要分为静态变量单例和动态分配单例两种方式。
优点是:在第一次调用时才会被初始化,因此可以把全局单例改为静态变量,控制构建次序。但缺点也很明显:不可控制析构次序,且很难预计单例确切构建时间。
要解决析构次序问题,可以在单例构建时,把自己登记在一个全局堆栈,main结束前,逐一把堆栈弹出调用终止函数,但有时候不能解决所有情况。
1.2.1 静态变量单例代码示例:
1 | class Manager |
1.2.2 动态分配单例代码示例:
1 | class Manager |
1.3 在main()中显式按次序调用启动终止函数✅️
简单可控,但手动维护易出错。
1 | class Game |
1.4 各个管理器注册到全局的有限队列,按恰当次序逐一启动所有管理器✅️
1.5 通过管理器列举依赖的管理器,定义管理器间的依赖图,按依赖关系计算最优的启动次序✅️
1.6 实际引擎的例子
- OGRE:
Ogre::Root单例统一启动和终止子系统(动态创建)。扩展需要修改Ogre::Root的构造函数和析构函数,违反开闭原则。 - 顽皮狗神秘海域/最后生还者引擎:可行情况避免动态内存分配,单例使用静态分配对象。
2. 内存管理
2.1 优化动态内存分配
- 维持最低限度的堆分配,并且永不再在凑循环中使用堆分配。
- 定制分配器的优势(可以参考Are we out of memory?):
- 预分配内存完成分配,在用户模式进行,不用进入内核模式切换上下文;
- 对使用模式设置不同的假设,比通用分配器高效。
2.2 常见的定制内存分配器
2.2.1 基于堆栈的分配器:
- 原理:分配一大块连续内存或一个全局字节数组,安排一个指针指向堆栈的顶端,指针以下的内存是已分配的,指针以上的内存是未分配的。对于每个分配或释放要求,移动指针即可。
- 特点:注意不能以任意次序释放内存,必须以分配时相反的次序释放内存。实现时可以提供一个函数把堆栈顶端指针回滚到之前标记的位置,释放从回滚点到目前堆栈顶端之间的所有内存。而回滚顶端指针时,回滚的位置必须在两个分配而来的内存块之间的边界。
- 代码示例实现:
1 | class StackAllocator |
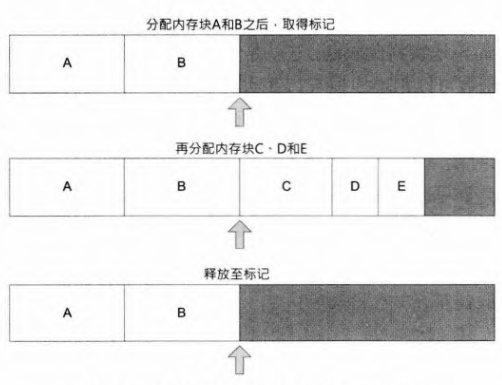
2.2.2 双端堆栈分配器
- 原理:一块内存可以给两个堆栈分配器使用,一个从内存块低端向上分配,另一个从顶端向下分配。比如底堆栈可以用来载入和卸载游戏关卡,顶堆栈可以用来分配临时内存块,临时内存在每帧分配及释放。

2.2.3 池分配器
- 场景:分配大量同等尺寸的小块内存,所以池内存是分配元素大小的倍数。
- 原理:池的元素可以放在一个链表里,初始化链表包含所有元素,当需要分配元素取出自由链表的下一个元素,释放则把元素放回链表。具体可以有以下几种分类和设计:
- 元素尺寸大于指针,自由块内存存储
next指针(union),分配时next指针被覆盖为真正的内容;
1 |
|
- 若元素尺寸小于指针,可以用池元素的索引代替指针实现链表(类似
union不表示元素的时候内存被当做next,里面的元素为索引)。
1 |
|
2.2.4 含对齐功能的分配器
-
原理:所有内存分配器都必须传回对齐的内存块,在分配内存时,分配比请求所需多一点的内存,向上调整内存地址至适当的对齐,传回调整后的地址。 重点是计算调整偏移量:用掩码把原来内存块地址的最低有效位取出,再用期望的对齐值减去它,就是调整偏移量。对齐应该是2的幂次,只要把对齐减一。比如16字节对齐,掩码就是
mask=16-1=15=0x0F,原地址为x,那么最后对齐的地址就是x + (0x0F - (x & mask))。 -
代码示例实现
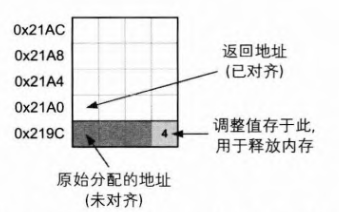
- 对齐分配函数:先多分配一段空间,再通过地址计算找到符合对齐要求的地址。注意释放要转换调整后的地址为原本的可能未对齐的地址。要完成这个转换需要存储元信息,在调整后地址之前的1字节存储偏移量即可,有了这个信息就可以还原原来的地址。
1 | // 对齐分配函数。注意,"alignment" 必须为2的幂(一般是4或16) |
- 释放对齐内存块:
1 | void freeAligned(void* pMem) |
2.2.5 单帧和双缓冲内存分配器
这一类内存分配器用于在游戏循环中分配一些临时数据,可以在循环迭代结束以后被丢弃,也可以在下一迭代结束时被丢弃。
2.2.5.1 单帧分配器
- 实现:预留一块内存,在每帧开始时,堆栈的顶端指针重置到内存块的底端地址,在该帧中,分配要求在堆栈不断成长,循环往复。
- 优点是分配的内存永远不手动释放,在每帧开始会清除所有内存,所以及其高效。缺点是程序员不能把指向单帧内存块的指针跨帧使用。
- 代码示例实现
1 | StackAllocator g_singleFrameAllocator; |
2.2.5.2 双缓冲分配器
- 双缓冲分配器允许在第i帧分配的内存块用于第i+1帧。实现方法是建立两个相同尺寸的单帧堆栈分配器,在每帧交替使用。
1 | class DoubleBufferedAllocator |
2.3 内存碎片
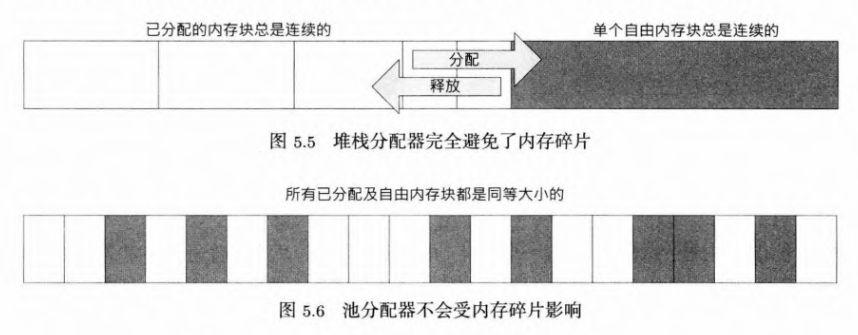
2.3.1 用堆栈和池分配器避免内存碎片
- 堆栈分配器:由于内存块以相反的次序被释放,所以不会产生碎片。
- 池分配器:池所有的内存块大小都是一样的。不会因缺乏足够大的块而分配失败。
2.3.2 碎片整理和重定位
- 碎片整理,类似下图。
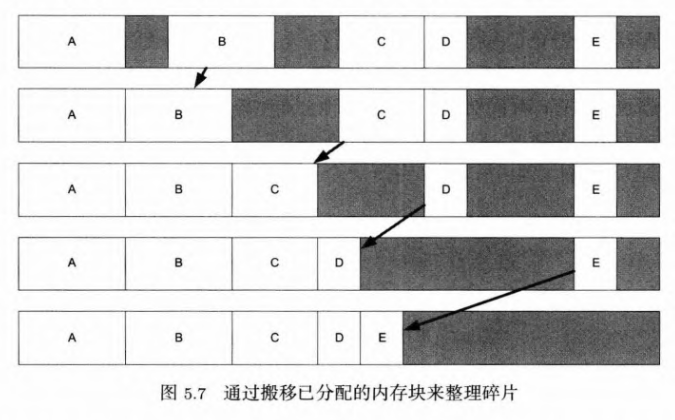
- 问题1:如果移动了已分配的内存,那么当有指针指向这些内存块也意味着这些指针会失效。
- 方案1:为解决碎片整理指针失效的问题,可以指针重定位,把指向这些内存块的指针逐一更新,使移动内存块后的指针指向新的内存块。但程序员需要手动维护正确才行。
- 方案2:另一种方法是舍弃指针,重定位使用智能指针或句柄:
- 智能指针:把所有智能指针添加自己到一个全局链表里,移动某块内存,扫描全局链表,更新指向这块内存的智能指针。
- 句柄:实现为索引,索引指向句柄表的元素,每个元素存储指针,移动内存,扫描句柄表,修改相应的指针,句柄只是索引,所以移动内存块,句柄值是不变的。
- 问题2:某些内存块可能无法重定位,比如第三方库的指针。
- 方案1:第三方库在另一个特别缓冲区里分配内存,此缓冲区位于可重定位内存范围之外。
- 方案2:允许一些内存块不能被重定位,如果内存块数量少并且体积少,那么可以接受。
- 问题3:碎片整理要复制内存块,操作过程可能很慢。
- 方案1:分帧整理,限制每帧最多进行N次内存块移动。
3. 容器
常见容器包括数组、动态数组、链表、堆栈、队列、双端队列、优先队列、树、二叉搜索树、字典、集合、图、有向无环图。
3.1 容器操作
常见容器操作包括插入、删除、查找、迭代、随机访问等。
3.2 迭代器
迭代器通常设计为容器的友元,简化了迭代过程。后置递增p++和前置递增++p,后置递增必须先递增才能使用值,这会产生数据依赖,引起流水线停顿stall,而使用p++则可立即使用变量的值,递增运算可以稍后进行或者并行执行,不会造成停顿。
3.3 算法复杂度
需要随机访问使用数组,需要插入或移除元素速度快使用链表。注意链表相比数组还会额外有内存开销(存储了next指针。
3.4 自定义容器
容器可以自己实现也可以使用第三方的实现,如果下面第三方的实现不够好,那么可以自己实现。
- STL
- 代码的重量级STL类会造成瓶颈,避免使用STL,例如三维网络中的每个顶点加一个
std::list不好,std::list会为每个元素动态分配细小的节点对象,会形成很多细小的内存碎片。 - 需要支持跨平台,推荐使用STLPort,比原来的STL高效,功能丰富。
- Boost
- Boost扩展了STL,提供了许多有用的功能。
- Boost文档写得好,会深入探讨开发该库的设计决定,可以用来学习软件设计原则。
- Boost都是模版,只要包含头文件,但会生成大的lib文件,可能不适合小型的游戏项目。
- Boost如果遇到bug需要自己修。而且不支持向后兼容。
- Boost使用需要小心阅读许可证内容。
- Loki
- 代码值得学习。
- 代码令人生畏,难以使用和全面理解。
- 移植不友好,但可以参考里面的基于原则的设计,可以参考一下书《C设计新思维》(Modern C Design)。
3.5 一些容器实现
3.5.1 数组
STL的数组索内存可以使用swap函数。
1 | std::vector<int> v = {1,2,3,4,5}; |
3.5.2 链表
- 外嵌式链表,优点是一个元素能置于多个链表中,只要给每个链表单独创建一个指向它的 Link 节点就行。缺点是每次插入都要动态分配 Link 节点。如果希望在链表存储一些实例,这些实例来自第三方库,又不想修改库代码,外露式表会成为唯一选择。
1 | template< typename ELEMENT > |
- 侵入式链表,优点是无需再动态分配节点,每次分配元素已经免费获得节点。缺点是每个元素不能同时置于多个链表中
- 实现1:
1 | class SomeElement |
- 实现2:使用继承,可以把节点指针(
Link<SomeElement>*)向下转型为指向元素本身的指针(SomeElement*),消去节点中指向元素的指针。
1 | template< typename ELEMENT > |
- 头尾指针:循环链表
- 单向链表
3.5.3 字典和散列表
- 哈希碰撞
- 开放式散列:键值对以链表存储。每次加入键值对需要动态分配内存。
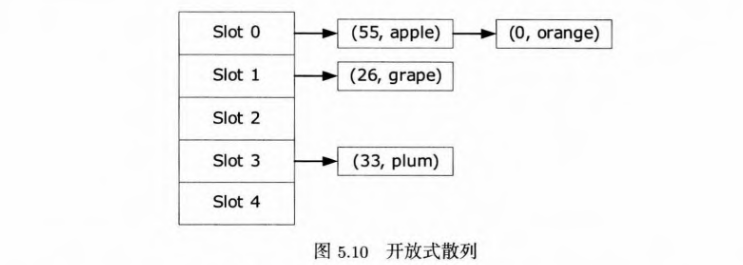
- 闭合式散列:探查直到找到空位,但是实现困难,必须设定表的键值对数目上限,优点是内存固定,不用动态分配内存。简单的探查法有线性探查、二次探查。建议把散列表设为质数大小,原因可以查看帖子。

- 散列把任意数据类型转换为整数,然后整数模表的大小得到表的索引,数学表达这两个过程为:
常见的字符串散列函数:
- LOOKUP3
- 循环冗余检验,如CRC32
- MD5,结果好,但是运算成果高
- Paul Hsieh的文章,介绍了一些散列函数的实现。
4. 字符串
4.1 字符串的使用问题
- 字符串要考虑本地化
4.2 字符串类
-
使用字符串类,要明确开销:是否把所有字符缓冲区当做刻度的,是否使用了写时复制,有没有提供移动构造函数。建议以引用形式传递对象,不要用值传递。
-
文件路径建议用类封装,因为不同操作系统的斜线不同。
4.3 唯一标识符
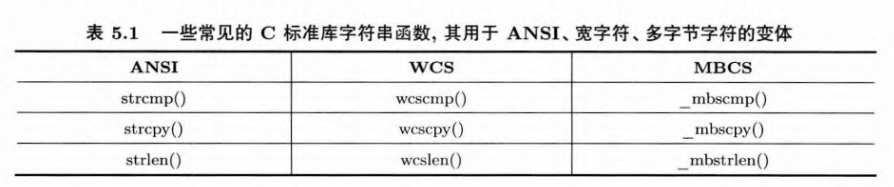
GUID:一般用64位或128位全局唯一标识符,比较不用strcmp,下面是一些方案:
- 字符串哈希,把字符串映射到唯一整数,然后整数比较。
4.4 本地化
介绍了不同编码,如Unicode(UTF-32, UTF-16, UTF-8)。char和wchar_t(大小因为编码可能有歧义)。
5. 引擎配置
5.1 读/写选项
- 文本配置文件,如ini,键值对分组
1 | [Graphics] |
- 压缩的二进制文件,数据紧凑。
- Windows注册表:树形结构。
- 命令行选项
- 环境变量
- 线上用户设定文档
5.2 个别用户选项
HKEY_CURRENT_USER是当前用户子树的别名,用户有其单独的注册表子树HKEY_USERS,读写HKEY_CURRENT_USER下的注册表项,就可以管理用户的配置选项。
5.3 引擎配置管理
可以关注一下Scheme数据定义,可以自动生成C/C++头文件,然后调用LookupSymbol()函数即可读取数据。