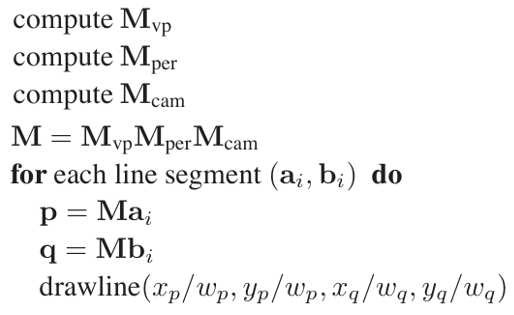计算机图形学基础
另外要注意的是:
-
运动的合成根据的是矩阵左乘规则,因为参考坐标系始终是固定坐标系。
-
下面的齐次坐标是等价的:
(x,y,z,1)≜(kx,ky,kz,k!=0)
例子:(1,0,0,1) 和(2,0,0,2) 都表示(1,0,0)
2 Viewing-观测
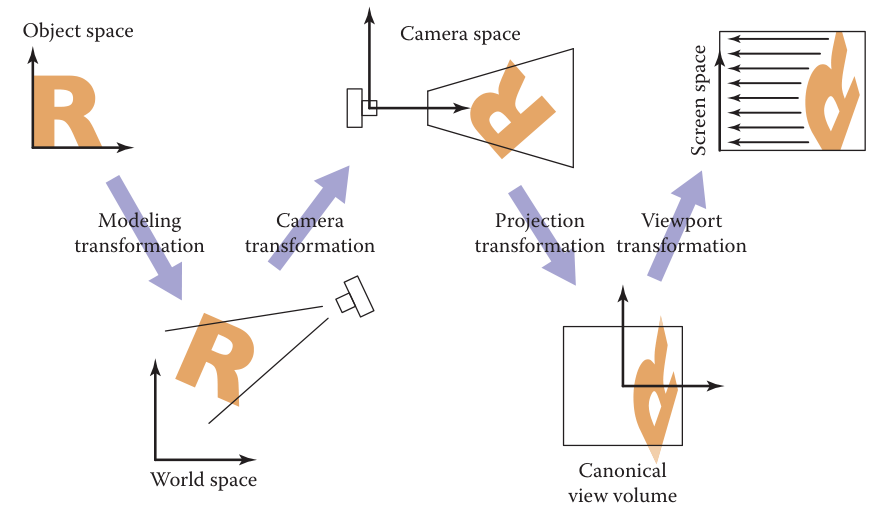
观测主要解决的问题是如何把物体的三维“模型”变成我们在屏幕所看到的二维“图片”,我们在计算机看到实体模型可以分成这样几步:
- 相机变换(camera transformation)或眼变换(eye transformation):想象把相机放在任意一个位置来观测物体,我们首先就要把物体的世界坐标转换为相机坐标,这一步称为相机变换或眼变换。
- 投影变换(projection transformation):相机把物体拍成照片本质是从三维的相机坐标转化为二维的平面坐标,这一步称为投影变换。投影可以分为正射投影和透视投影。
- 视口变换(viewport transformation)或窗口变换(windowing transformation):相机拍成的图片最后是要显示在屏幕上,我们需要把二维的图片坐标再转换为电脑屏幕的像素坐标,这一步称为视口变换或窗口变换。
下面这个照相的类比非常地生动形象。
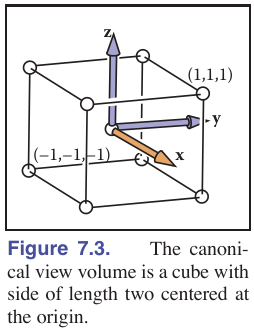
一般来说,我们规定相机沿着−z方向,在观测过程中为了简化会使用canonical view volume(CCV):它是一个正方体,x,y,z坐标都位于−1到1之间,也即(x,y,z)∈[−1,1]3,我们将x=−1投影到电脑屏幕的左侧,将x=+1投影到屏幕的右侧,将y=−1投影到屏幕的底部,将y=+1投影到屏幕的顶部。
canonical view volume(CCV)
如果我们定义屏幕每个像素的长和宽为1,最小的像素中心坐标是(0,0),则图像的中心到其边界为0.5,如果屏幕上的像素总长度为nx,总宽度为ny,那么我们可以将canonical view volume(CCV)的xoy平面的方形[−1,1]2映射为长方形[−0.5,nx−0.5]×[−0.5,ny−0.5]。
注意我们现在假设所有的线都在CCV正方体里,后面这个假设将在讲裁剪的时候放松这个条件。
对于视口变换,我们需要想把CCV正方体的xoy平面进行放缩然后将原点平移到屏幕的左下角(CCV的原点在xoy正方形的正中心),其可以写作一个二维的变换【这里相当于计算上面的线性映射:−1→−0.5,1→nx−0.5(或ny−0.5)】:
⎣⎢⎡xscreen yscreen 1⎦⎥⎤=⎣⎢⎡2nx0002ny02nx−12ny−11⎦⎥⎤⎣⎢⎡xcanonical ycanonical 1⎦⎥⎤
这里忽略了z轴的坐标,因为投影最终和z坐标无关,这里我们可以扩充矩阵(尽管在这里没有用):
Mvp=⎣⎢⎢⎢⎡2nx00002ny0000102nx−12ny−101⎦⎥⎥⎥⎤
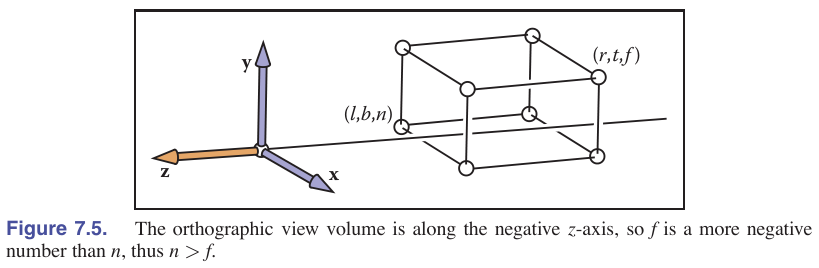
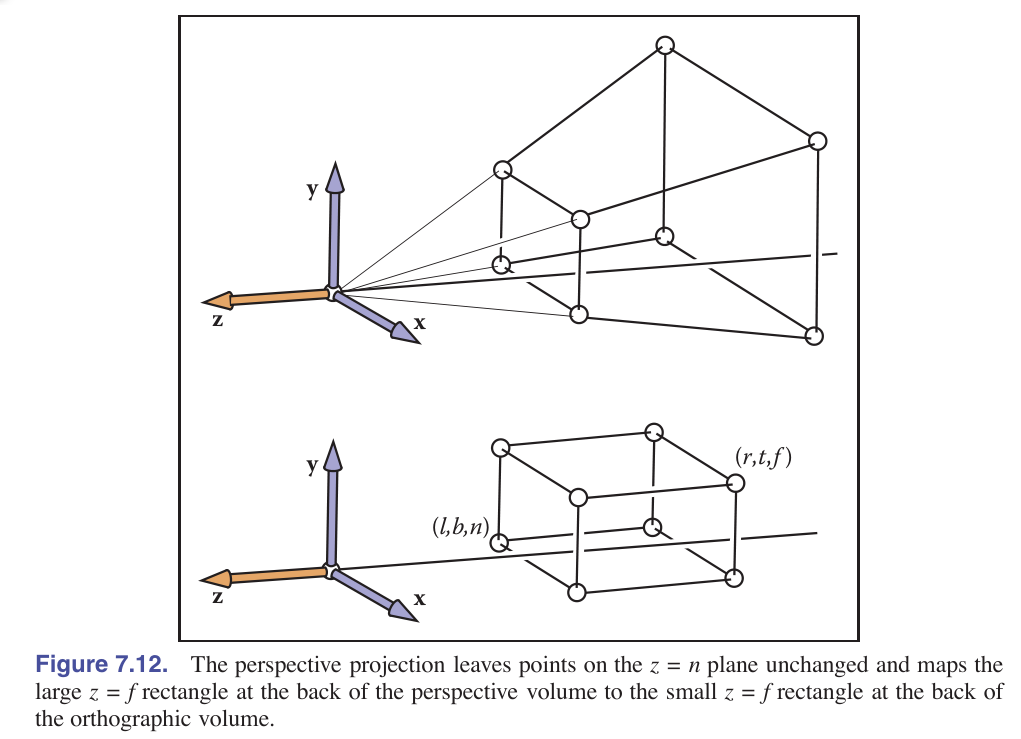
我们通常想把在渲染某个空间区域的几何元素而不是CCV,我们要调整我们的坐标轴的方向来实现正射变换,让坐标轴的−z轴对着物体,让y轴朝上,x轴按照右手定则定义。我们看到的view volume是一个[l,r]×[b,t]×[f,n]的box。
关于l,r,b,y,f,n的物理含义可以看下面的表格:
| plane |
meaning |
plane |
meaning |
| x=l |
left plane |
x=r |
right plane |
| y=b |
bottom plane |
y=t |
top plane |
| z=n |
near plane |
z=f |
far plane |
我们同样可以写出变换矩阵把这个box映射为CCV(参考原书公式的6.7,英文原版132页),变换的好处是简化数字在−1到1之间,方便后续计算:
Morth =⎣⎢⎢⎢⎡r−l20000t−b20000n−f200001⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡100001000010−2r+l−2t+b−2n+f1⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡r−l20000t−b20000n−f20−r−lr+l−t−bt+b−n−fn+f1⎦⎥⎥⎥⎤
现在我们可以转换视角中任意看到的点(x,y,z)在像素上看到的位置(xpixel,ypixel,zcanonical)
⎣⎢⎢⎢⎡xpixel ypixel zcanonical 1⎦⎥⎥⎥⎤=(MvpMorth )⎣⎢⎢⎢⎡xyz1⎦⎥⎥⎥⎤
CCV坐标变换至屏幕坐标直线算法流程:
z坐标的范围是[−1,1],现在我们还没有用到,这将在z-buffer算法时很有用。
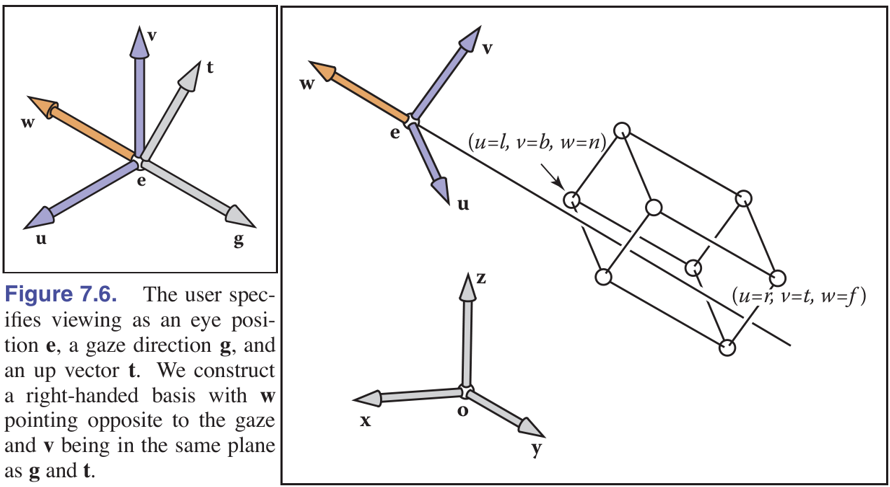
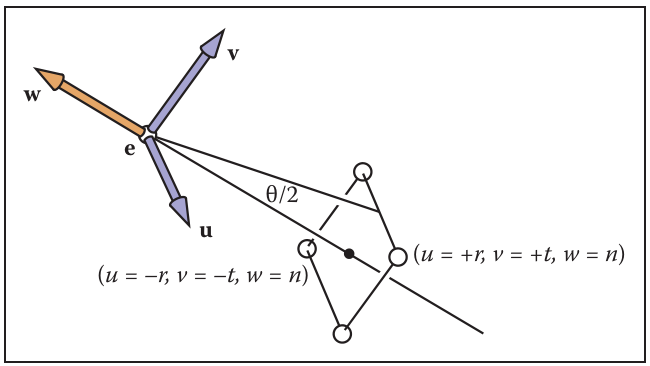
当我们需要改变3D视角和观测的方向时,我们需要重新定义观测者的位置和方向(改变相机的放置位置)。可以定义相机坐标系,我们期望的相机的朝向可以由两个向量g和向量t来定义,以及一个点e来表示。
- e:相机位置
- g:观测方向
- t:上视方向
于是我们可以根据上面所说的向量和电定义我们的相机坐标系uvw(世界坐标系是xyz),其中坐标系的原点就是e,v轴和t矢量方向相同,w轴和−g矢量方向相同,u轴根据右手定则确定。
wuv=−∥g∥g=∥t×w∥t×w=w×u
接下来我们会把世界坐标系的点坐标转换到相机坐标系中。我们可以把变换矩阵分解为两步,先平移再旋转。
由于将坐标系uvw转换为坐标系xyz的变换矩阵可以看做是
Mcam−1=[u0v0w0e1]
相机坐标系是要将坐标系xyz转换到坐标系uvw,于是这等价于对矩阵求一个逆。
Mcam=[u0v0w0e1]−1=⎣⎢⎢⎢⎡xuxvxw0yuyvyw0zuzvzw00001⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡100001000010−xe−ye−ze1⎦⎥⎥⎥⎤
世界坐标正式投影变换至屏幕坐标画直线算法流程:
投影变换符合我们的视觉直观,主要体现在有近大远小的特性,平行线相交于一点。在实际的计算机图形中用得更多。
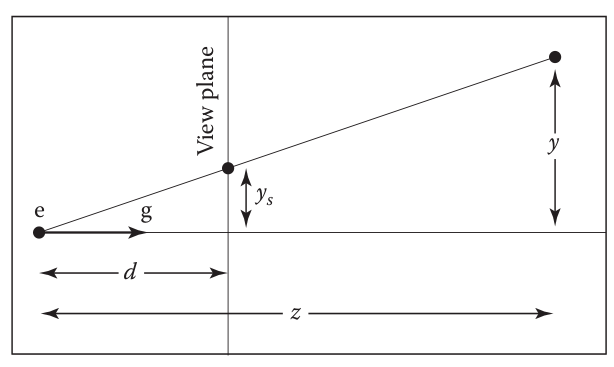
如上图所示,我们从视点e沿着g方向看,看到的实际的点的高度为y,反映在观察平面上高度为ys,观察平面距离视点为d,实际的点距离视点为z,根据简单的相似三角形的关系,我们有(这里我们认为z是距离,为正数,而不是坐标意义下的负数):
ys=zdy
虎书里还提到了线性有理变换,这里把变换矩阵简单写一下(感兴趣可以直接看虎书)
⎣⎢⎢⎢⎡x~y~z~w~⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡a1a2a3eb1b2b3fc1c2c3gd1d2d3h⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡xyz1⎦⎥⎥⎥⎤
(x′,y′,z′)=(x~/w~,y~/w~,z~/w~)
上面的第二个公式刚好使用了[1-Transformation Matrix-变换]中注意的第二点:齐次坐标的等价性。使用上述的变换可以进行下面的操作:
前面我们已经讲了二维的情况。但是我们实际要处理的是三维的情况。经过投影变换就好像把一个棱台给变成了一个轴平行的box。这将方便我们使用正交投影变换矩阵变成CCV。
这里我们就搬出之前在[Camera Transformation-相机变换]所建立的坐标系,我们依然使用z=n近端平面和z=f远端平面,并使用z=n近端平面作为观察平面。需要注意的是,上面的n和z在坐标系定义下都是小于0的。对于投影变换后的xs和ys,类似前面二维情况:
ys=znyxs=znx
我们可以整理成矩阵的形式:
⎝⎜⎜⎜⎛xyz1⎠⎟⎟⎟⎞⇒⎝⎜⎜⎜⎛nx/zny/zunknown1⎠⎟⎟⎟⎞≜⎝⎜⎜⎜⎛nxnyunknownz⎠⎟⎟⎟⎞
于是我们所要求的投影变换矩阵满足:
P⎝⎜⎜⎜⎛xyz1⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛nxnyunknownz⎠⎟⎟⎟⎞⇒P=⎝⎜⎜⎜⎛n0?00n?000?100?0⎠⎟⎟⎟⎞
那么zs是多少呢?对投影变换我们注意到:
-
近端平面z=n的点映射以后点不发生变化。
-
远端平面z=f的点映射以后z坐标不变。
根据第(1)点:近端平面z=n的点映射以后点不发生变化。我们有:
P⎝⎜⎜⎜⎛xyn1⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛xyn1⎠⎟⎟⎟⎞≜⎝⎜⎜⎜⎛nxnyn21⎠⎟⎟⎟⎞
所以P的第三行形式为(00AB),前两个元素为0是因为该齐次坐标的z坐标为n2,和x,y的取值无关。我们单独拿出第三行和齐次坐标相乘有:
(00AB)⎝⎜⎜⎜⎛xyn1⎠⎟⎟⎟⎞=n2⇒An+B=n2
根据第(2)点:远端平面z=f的点映射以后z坐标不变。我们有:
⎝⎜⎜⎜⎛00f1⎠⎟⎟⎟⎞⇒⎝⎜⎜⎜⎛00f1⎠⎟⎟⎟⎞≜⎝⎜⎜⎜⎛00f2f⎠⎟⎟⎟⎞⇒Af+B=f2
于是我们有:
{An+B=n2Af+B=f2⇒{A=n+fB=−nf
这样我们就确定了投影变换的变换矩阵:
P=⎣⎢⎢⎢⎡n0000n0000n+f100−fn0⎦⎥⎥⎥⎤
经过投影变换最终我们看到坐标发生了如下的变化:
P⎣⎢⎢⎢⎡xyz1⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡nxny(n+f)z−fnz⎦⎥⎥⎥⎤≜⎣⎢⎢⎢⎡znxznyn+f−zfn1⎦⎥⎥⎥⎤
有时候我们想把屏幕坐标变换回世界坐标,这时候我们就需要用到P的逆矩阵:
P−1=⎣⎢⎢⎢⎡n10000n100000−fn1001fnn+f⎦⎥⎥⎥⎤≜⎣⎢⎢⎢⎡f0000f00000−100fnn+f⎦⎥⎥⎥⎤
完整的透视变换包括了正视变换和投影变换的组合,先处理近大远小的投影变换为box,然后把box变回一个CCV。
Mper=MorthP=⎣⎢⎢⎢⎡r−l2n0000t−b2n00l−rl+rb−tb+tn−ff+n100f−n2fn0⎦⎥⎥⎥⎤
在OpenGL中,这一矩阵的定义可能不一样:
MOpenGL =⎣⎢⎢⎢⎢⎡r−l2∣n∣0000t−b2∣n∣00r−lr+lt−bt+b∣n∣−∣f∣∣n∣+∣f∣−100∣n∣−∣f∣2∣f∣∣n∣0⎦⎥⎥⎥⎥⎤
这里我们使用了Morth,随之而来的问题是:Morth中的l,r,t,b这些值怎么定义呢,它们定义了我们的窗口看到的物体,由于近端平面z=n的x和y不变,我们这里选择了近端平面z=n来定义l,r,t,b。
我们最后来看一下从相机坐标经过透视变换到屏幕坐标的算法流程:
2.5 Field-of-View-视场
我们通过(l,r,t,b)和n定义我们的窗口,我们可以进一步简化,如果我们屏幕的中心是原点,那么有:
lb=−r,=−t.
另外我们可以添加每个像素是正方形的约束,使得图形没有形状的畸变,我们使用的r和t一定要和水平像素数nx和竖直像素数ny成比例:
nynx=tr
当nx和ny被确定以后,只剩下一个自由度,我们经常使用θ作为视场,下图为垂直视场,它满足关系:
tan2θ=∣n∣t
通过确定n和θ,我们就可以计算t来得到更一般的观测系统。
3 Graphics Pipeline-图形管线
渲染的第二种主要方法是逐个将对象绘制到屏幕上,也称为物体顺序渲染。与后面讲到的光线追踪不同,在光线追踪中我们逐个考虑每个像素并找到影响其颜色的对象,现在我们将逐个考虑每个几何对象并找到它可能影响的像素(说得有点拗口哈哈)。
找到图像中由几何图元占据的所有像素的过程称为光栅化,因此物体顺序渲染也可以称为光栅化渲染。执行从对象开始到更新图像像素结束的一系列操作被称为图形管线。
当然,物体顺序渲染不只有一种方法——两个非常不同的图形管线示例是用于通过OpenGL和Direct3D等API支持交互式渲染的硬件管线,以及用于电影制作的支持RenderMan等API的软件管线。硬件管线必须以足够快的速度运行,以实时响应游戏、可视化和用户界面。软件管线必须呈现最高质量的动画和视觉效果,并能适应庞大的场景,但可能需要更长的渲染时间。
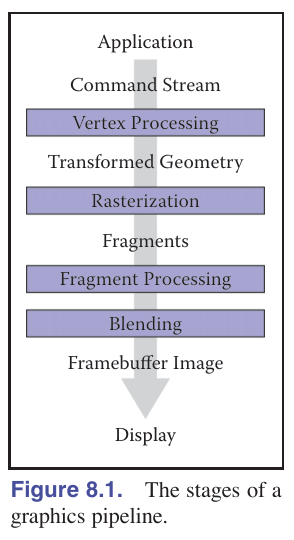
图形管线可以分为四个阶段:顶点处理、光栅化、片段处理和片段混合。
几何对象通过交互应用程序或场景描述文件输入到管线中,并且始终由一组顶点描述。顶点处理阶段对顶点进行操作,然后使用这些顶点生成基本图元发送到光栅化阶段。
物体顺序渲染的工作可以分为三个阶段:光栅化、光栅化前的几何操作和光栅化后的像素操作。几何操作中最常见的操作是应用矩阵变换,将定义几何形状的点从物体空间映射到屏幕空间,以便输入到光栅化器时以像素坐标或屏幕空间表示。像素操作中最常见的操作是隐藏面消除,使离观察者更近的表面显示在离观察者更远的表面之前。
光栅化器将每个基本图元分解为一组片段(fragment),每个片段对应于被基本图元覆盖的像素。片段处理阶段处理各个片段,然后在片段混合阶段中将每个像素对应的片段进行合并。下面是图形管线的示意图。
3.1 光栅化